Als ich in die Webentwicklung einstieg (2005-2010 waren prägende Jahre für mich), war eine der ersten Lektionen, die ich lernte, eine saubere HTML-Grundlage zu haben. „Wie schöner HTML-Code aussieht“ ist tatsächlich einer der beliebtesten Beiträge auf dieser Seite. Das Bild in diesem Beitrag schaffte es ab und zu auf beliebte Seiten auf Subreddits.
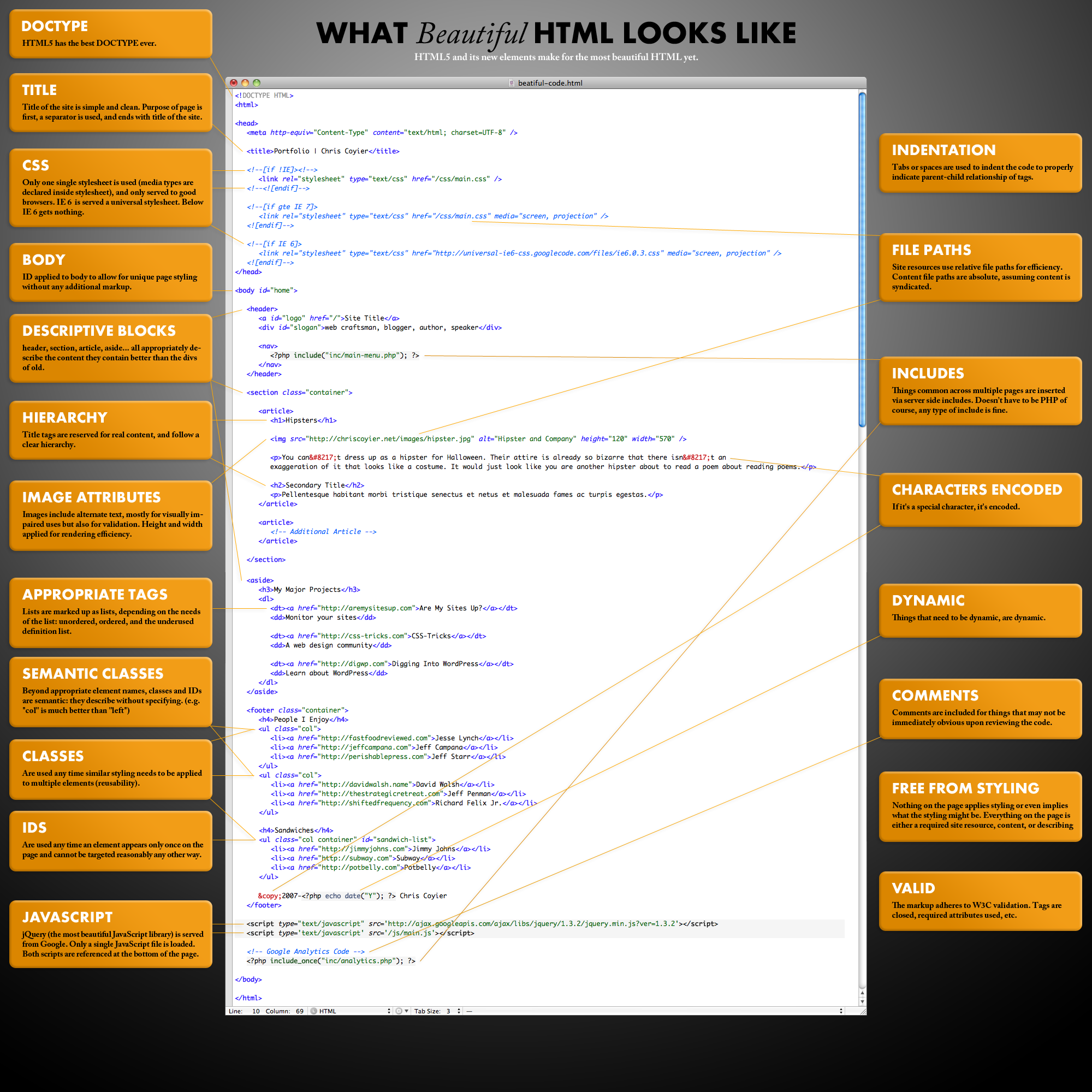{kind=link}
Nun, während ich standardmäßig immer noch HTML wie diesen schreibe, wenn ich an Seiten wie dieser arbeite, arbeite ich auch an Projekten, die gar keinen solchen HTML-Output haben. Ich arbeite nicht für Twitter, aber hier ist, was Sie sehen könnten, wenn Sie die DevTools öffnen und den DOM dort inspizieren.

Niemand würde das als „sauberes“ HTML bezeichnen. Tatsächlich ist es nicht schwer, Kritik daran zu vermuten. Warum all die divs! Divitis!! Ist das wirklich ein <div role="button">, komm schon. Das sind furchtbare Klassennamen! Robotergekotze!
Was wahrscheinlich näher an der Wahrheit liegt, ist, dass es eigentlich nicht so wichtig ist. Es ist nicht so, dass Semantik keine Rolle spielt. Es ist nicht so, dass Barrierefreiheit keine Rolle spielt. Es ist nicht so, dass Performance keine Rolle spielt. Es ist, dass dieser Output tatsächlich diese Dinge recht gut macht, oder zumindest so gut, wie sie es beabsichtigen.
Giuseppe Gurgone geht ins Detail.
React Native for Web bietet plattformübergreifende Primitiven, die Inkonsistenzen normalisieren und den Aufbau von Webanwendungen ermöglichen, die unter anderem Touch-freundlich sind.
Für jemanden, der mit dem Framework nicht vertraut ist, mag das von React Native for Web erzeugte HTML völlig hässlich und voller schlechter Praktiken aussehen.
Dieser DOM erzeugt tatsächlich einen erwarteten und nutzbaren Barrierefreiheitsbaum. Die <div>s mit Rollen dienen dazu, bestimmte plattformübergreifende Styling-Einschränkungen zu überwinden. Diese Klassen stammen aus einem Styling-Framework, das beim Scoping von CSS hilft. Es sieht verrückt aus, aber alles hat einen Grund.
Das soll nicht heißen, dass all dies außerhalb jeder Kritik steht. Man könnte argumentieren, dass roboterhafte Klassennamen keine benutzerdefinierten Stylesheets zulassen, die bei der Barrierefreiheit helfen könnten. Man könnte argumentieren, dass die überflüssigen divs einen unnötig schweren DOM ausmachen. Man könnte argumentieren, dass das Ausliefern von Robotergekotze das Web weniger erlernbar macht, insbesondere ohne Source Maps.
Es gibt Dinge zu besprechen, aber nur eine Menge von divs mit seltsamen Klassennamen zu sehen bedeutet nicht, dass es schlechter Code ist. Und es ist auch nicht auf React Native beschränkt, viele Frameworks haben ihre eigenen besonderen Eigenheiten in dem, was sie tatsächlich an Browser ausliefern, und das dient fast immer dazu, die Website auf irgendeine Weise besser funktionieren zu lassen, nicht um beim Lehren oder der Lesbarkeit zu helfen.
Es gibt eine nicht zu vernachlässigende Begründung für diese Markup, nämlich dass es die programmatische Extraktion durch Bibliotheken wie lxml oder Beautiful Soup erschwert.
Dies verlagert „Datenerfassungsanwendungsfälle“ für Twitter vom Web zur Twitter API, wo Twitter die Raten und den Zugriff leichter kontrollieren kann. Mission erfüllt.
Das ist ein Schutz gegen Scraper. Ich habe versucht, einen zu verwenden, konnte ihn aber nicht zum Laufen bringen.
Das ist tatsächlich der Grund für diese „roboterhafte“ DOM-Konstruktion. Und zum Beitrag im Allgemeinen gibt es keine Entschuldigung, abgesehen von Sicherheit durch Obskurität (gegen Scraper), um keine leichte und schnelle Web-App zu bauen. Man braucht keinerlei Obfuskation, um sie auf Touch-Geräten besser funktionieren zu lassen, das ergibt keinen Sinn!
Das hilft aber nicht gegen Scraper, da irgendwo am Ende dieser verschachtelten Hölle ein einzelner
<article>ist. Seine Struktur ist ziemlich statisch, so dass er trotzdem problemlos von einem Scraper durchlaufen werden kann.