Diese zweiteilige Serie ist eine sanfte, oberflächliche Einführung in die Offline-Webentwicklung. In Teil 1 haben wir einen grundlegenden Service Worker zum Laufen gebracht, der unsere Anwendungsressourcen cacht. Nun erweitern wir ihn, um Offline-Unterstützung zu bieten.
Artikelserie
- Das Setup
- Die Implementierung (hier sind Sie!)
Erstellen einer `offline.htm`-Datei
Als Nächstes fügen wir Code hinzu, um zu erkennen, wann die Anwendung offline ist, und leiten unsere Benutzer gegebenenfalls zu einer (gecachten) `offline.htm` um.
Aber halt, wenn die Service-Worker-Datei automatisch generiert wird, wie fügen wir unseren eigenen Code manuell hinzu? Nun, wir können einen Eintrag für importScripts hinzufügen, der unserem Service Worker mitteilt, die von uns angegebenen Skripte zu importieren. Dies geschieht über die native `importScripts`-Funktion des Service Workers, die gut benannt ist. Und wir werden auch unsere `offline.htm`-Datei zu unserer statisch gecachten Liste von Dateien hinzufügen. Die neuen Dateien sind unten hervorgehoben
new SWPrecacheWebpackPlugin({
mergeStaticsConfig: true,
filename: "service-worker.js",
importScripts: ["../sw-manual.js"],
staticFileGlobs: [
//...
"offline.htm"
],
// the rest of the config is unchanged
})Gehen wir nun in unsere `sw-manual.js`-Datei und fügen Code hinzu, um die gecachte `offline.htm`-Datei zu laden, wenn der Benutzer offline ist.
toolbox.router.get(/books$/, handleMain);
toolbox.router.get(/subjects$/, handleMain);
toolbox.router.get(/localhost:3000\/$/, handleMain);
toolbox.router.get(/mylibrary.io$/, handleMain);
function handleMain(request) {
return fetch(request).catch(() => {
return caches.match("react-redux/offline.htm", { ignoreSearch: true });
});
}Wir verwenden das `toolbox.router`-Objekt, das wir zuvor gesehen haben, um alle unsere Top-Level-Routen abzufangen, und wenn die Hauptseite nicht aus dem Netzwerk geladen wird, senden wir die (hoffentlich gecachte) `offline.htm`-Datei zurück.
Dies ist einer der wenigen Fälle in diesem Beitrag, in denen Promises direkt verwendet werden, anstatt mit der async-Syntax, hauptsächlich weil es in diesem Fall tatsächlich einfacher ist, einfach ein `.catch()` anzuhängen, anstatt einen `try{} catch{}`-Block einzurichten.
Die `offline.htm`-Datei wird ziemlich einfach sein, nur etwas HTML, das gecachte Bücher aus IndexedDB liest und sie in einer rudimentären Tabelle anzeigt. Aber bevor wir das zeigen, gehen wir durch, wie man IndexedDB tatsächlich benutzt (wenn Sie es jetzt sehen möchten, es ist hier)
Hallo Welt, IndexedDB
IndexedDB ist eine In-Browser-Datenbank. Sie ist ideal für die Aktivierung von Offline-Funktionen, da sie ohne Netzwerkverbindung zugänglich ist, aber keineswegs darauf beschränkt ist.
Die API ist älter als Promises, daher ist sie callback-basiert. Wir werden alles mit der nativen API durchgehen, aber in der Praxis werden Sie sie wahrscheinlich wrappen und vereinfachen wollen, entweder mit Ihren eigenen Hilfsmethoden, die die Funktionalität mit Promises wrappen, oder mit einem Drittanbieter-Tool.
Ich wiederhole: Die API für IndexedDB ist schrecklich. Hier sagt Jake Archibald, dass er sie nicht einmal direkt unterrichten würde
Ich unterrichte immer die zugrunde liegende API statt einer Abstraktion, aber für IDB würde ich eine Ausnahme machen.
— Jake Archibald (@jaffathecake) 2. Dezember 2017
Wir werden sie trotzdem durchgehen, weil ich wirklich möchte, dass Sie alles sehen, wie es ist, aber bitte lassen Sie sich davon nicht abschrecken. Es gibt viele vereinfachende Abstraktionen da draußen, zum Beispiel dexie und idb.
Einrichten unserer Datenbank
Fügen wir Code zu `sw-manual` hinzu, der sich an das `activate`-Ereignis des Service Workers bindet und prüft, ob wir bereits eine IndexedDB eingerichtet haben; wenn **nicht**, erstellen wir sie und füllen sie dann mit Daten.
Zuerst der Teil des Erstellens.
self.addEventListener("activate", () => {
//1 is the version of IDB we're opening
let open = indexedDB.open("books", 1);
//should only be called the first time, when version 1 does not exist
open.onupgradeneeded = evt => {
let db = open.result;
//this callback should only ever be called upon creation of our IDB, when an upgrade is needed
//for version 1, but to be doubly safe, and also to demonstrade this, we'll check to see
//if the stores exist
if (!db.objectStoreNames.contains("books") || !db.objectStoreNames.contains("syncInfo")) {
if (!db.objectStoreNames.contains("books")) {
let bookStore = db.createObjectStore("books", { keyPath: "_id" });
bookStore.createIndex("imgSync", "imgSync", { unique: false });
}
if (!db.objectStoreNames.contains("syncInfo")) {
db.createObjectStore("syncInfo", { keyPath: "id" });
evt.target.transaction
.objectStore("syncInfo")
.add({ id: 1, lastImgSync: null, lastImgSyncStarted: null, lastLoadStarted: +new Date(), lastLoad: null });
}
evt.target.transaction.oncomplete = fullSync;
}
};
});Der Code ist unübersichtlich und manuell; wie gesagt, Sie werden wahrscheinlich Abstraktionen hinzufügen wollen. Einige der wichtigsten Punkte: Wir prüfen, ob die von uns verwendeten objectStores (Tabellen) vorhanden sind, und erstellen sie bei Bedarf. Beachten Sie, dass wir sogar Indizes erstellen können, die wir beim Books-Store sehen, mit dem `imgSync`-Index. Wir erstellen auch einen `syncInfo`-Store (Tabelle), in dem wir Informationen darüber speichern, wann wir unsere Daten zuletzt synchronisiert haben, damit wir unsere Server nicht zu häufig mit Update-Anfragen belästigen.
Wenn die Transaktion abgeschlossen ist, rufen wir ganz unten die Methode `fullSync` auf, die alle unsere Daten lädt. Sehen wir uns an, wie das aussieht.
Durchführung einer initialen Synchronisierung
Unten sehen Sie den relevanten Teil des Synchronisierungscodes, der wiederholt unsere Endpunkte aufruft, um unsere Bücher seitenweise zu laden, und jedes Ergebnis dabei in IndexedDB speichert. Auch hier werden null Abstraktionen verwendet, erwarten Sie also viel Bloat.
Sehen Sie sich diesen GitHub Gist für den vollständigen Code an, der zusätzliche Fehlerbehandlung und Code enthält, der ausgeführt wird, wenn die letzte Seite fertig ist.
function fullSyncPage(db, page) {
let pageSize = 50;
doFetch("/book/offlineSync", { page, pageSize })
.then(resp => resp.json())
.then(resp => {
if (!resp.books) return;
let books = resp.books;
let i = 0;
putNext();
function putNext() { //callback for an insertion, with indicators it hasn't had images cached yet
if (i < pageSize) {
let book = books[i++];
let transaction = db.transaction("books", "readwrite");
let booksStore = transaction.objectStore("books");
//extend the book with the imgSync indicated, add it, and on success, do this for the next book
booksStore.add(Object.assign(book, { imgSync: 0 })).onsuccess = putNext;
} else {
//either load the next page, or call loadDone()
}
}
});
}Die Funktion `putNext()` ist, wo die eigentliche Arbeit geleistet wird. Dies dient als Callback für den Erfolg jeder erfolgreichen Einfügung. In der realen Welt hätten wir hoffentlich eine schöne Methode, die jedes Buch hinzufügt, eingepackt in ein Promise, damit wir eine einfache `for of`-Schleife verwenden und jede Einfügung `await`en könnten. Aber das ist die "Vanilla"-Lösung oder zumindest eine davon.
Wir modifizieren jedes Buch vor dem Einfügen, um die Eigenschaft `imgSync` auf 0 zu setzen, um anzuzeigen, dass dieses Buch sein Bild noch nicht gecacht hat.
Und nachdem wir die letzte Seite erschöpft haben und keine Ergebnisse mehr vorhanden sind, rufen wir `loadDone()` auf, um einige Metadaten einzustellen, die angeben, wann wir das letzte Mal eine vollständige Datensynchronisierung durchgeführt haben.
In der realen Welt wäre dies ein guter Zeitpunkt, all diese Bilder zu synchronisieren, aber stattdessen machen wir das bei Bedarf von der Webanwendung selbst, um eine weitere Funktion von Service Workern zu demonstrieren.
Kommunikation zwischen Web-App und Service Worker
Tun wir einfach so, als wäre es eine gute Idee, die Cover der Bücher beim nächsten Besuch unserer Seite, wenn der Service Worker läuft, zu laden. Lassen Sie uns unsere Web-App eine Nachricht an den Service Worker senden, und der Service Worker wird sie empfangen und dann die Buchcover synchronisieren.
Von unserem App-Code aus versuchen wir, eine Nachricht an einen laufenden Service Worker zu senden, der ihn anweist, Bilder zu synchronisieren.
In der Web-App
if ("serviceWorker" in navigator) {
try {
navigator.serviceWorker.controller.postMessage({ command: "sync-images" });
} catch (er) {}
}In `sw-manual.js`
self.addEventListener("message", evt => {
if (evt.data && evt.data.command == "sync-images") {
let open = indexedDB.open("books", 1);
open.onsuccess = evt => {
let db = open.result;
if (db.objectStoreNames.contains("books")) {
syncImages(db);
}
};
}
});In sw-manual haben wir Code, der diese Nachricht abfängt und die Methode `syncImages()` aufruft. Sehen wir uns das als Nächstes an.
function syncImages(db) {
let tran = db.transaction("books");
let booksStore = tran.objectStore("books");
let idx = booksStore.index("imgSync");
let booksCursor = idx.openCursor(0);
let booksToUpdate = [];
//a cursor's onsuccess callback will fire for EACH item that's read from it
booksCursor.onsuccess = evt => {
let cursor = evt.target.result;
//if (!cursor) means the cursor has been exhausted; there are no more results
if (!cursor) return runIt();
let book = cursor.value;
booksToUpdate.push({ _id: book._id, smallImage: book.smallImage });
//read the next item from the cursor
cursor.continue();
};
async function runIt() {
if (!booksToUpdate.length) return;
for (let book of booksToUpdate) {
try {
//fetch, and cache the book's image
await preCacheBookImage(book);
let tran = db.transaction("books", "readwrite");
let booksStore = tran.objectStore("books");
//now save the updated book - we'll wrap the IDB callback-based opertion in
//a manual promise, so we can await it
await new Promise(res => {
let req = booksStore.get(book._id);
req.onsuccess = ({ target: { result: bookToUpdate } }) => {
bookToUpdate.imgSync = 1;
booksStore.put(bookToUpdate);
res();
};
req.onerror = () => res();
});
} catch (er) {
console.log("ERROR", er);
}
}
}
}Wir öffnen den `imageSync`-Index von zuvor und lesen alle Bücher aus, die eine Null haben, was bedeutet, dass ihre Bilder noch nicht synchronisiert wurden. `booksCursor.onsuccess` wird immer wieder aufgerufen, bis keine Bücher mehr übrig sind. Ich verwende dies, um sie alle in ein Array zu legen, an welchem Punkt ich die Methode `runIt()` aufrufe, die sie durchläuft und `preCacheBookImage()` für jedes aufruft. Diese Methode wird das Bild cachen und, wenn keine unvorhergesehenen Fehler auftreten, das Buch in IDB aktualisieren, um anzuzeigen, dass `imgSync` nun 1 ist.
Wenn Sie sich fragen, warum in aller Welt ich mir die Mühe mache, alle Bücher vom Cursor in ein Array zu speichern, bevor ich `runIt()` aufrufe, anstatt einfach die Ergebnisse des Cursors durchzugehen und dabei zu cachen und zu aktualisieren, nun – es stellt sich heraus, dass Transaktionen in IndexedDB etwas seltsam sind. Sie werden abgeschlossen, wenn Sie die Ereignisschleife verlassen, es sei denn, Sie verlassen die Ereignisschleife in einer von der Transaktion bereitgestellten Methode. Wenn wir also die Ereignisschleife verlassen, um andere Dinge zu tun, wie eine Netzwerkanfrage zum Herunterladen eines Bildes, dann wird die Transaktion des Cursors abgeschlossen, und wir erhalten einen Fehler, wenn wir später versuchen, daraus zu lesen.
Manuelles Aktualisieren des Caches.
Lassen Sie uns das abschließen und uns die Methode `preCacheBookImage` ansehen, die tatsächlich ein Cover-Bild herunterlädt und es zum relevanten Cache hinzufügt (aber nur, wenn es noch nicht vorhanden ist).
async function preCacheBookImage(book) {
let smallImage = book.smallImage;
if (!smallImage) return;
let cachedImage = await caches.match(smallImage);
if (cachedImage) return;
if (/https:\/\/s3.amazonaws.com\/my-library-cover-uploads/.test(smallImage)) {
let cache = await caches.open("local-images1");
let img = await fetch(smallImage, { mode: "no-cors" });
await cache.put(smallImage, img);
}
}Wenn das Buch kein Bild hat, sind wir fertig. Als Nächstes prüfen wir, ob es bereits gecacht ist – wenn ja, sind wir fertig. Zuletzt inspizieren wir die URL und ermitteln, in welchen Cache sie gehört.
Der Cache-Name `local-images1` ist derselbe wie zuvor, den wir in unserem dynamischen Cache eingerichtet haben. Wenn das betreffende Bild noch nicht vorhanden ist, holen wir es ab und fügen es zum Cache hinzu. Jeder Cache-Vorgang gibt ein Promise zurück, so dass die async/await-Syntax die Dinge schön vereinfacht.
Testen Sie es aus
So wie es eingerichtet ist, wenn wir unseren Service Worker entweder in den Dev Tools unten oder durch Öffnen eines frischen Inkognito-Fensters löschen…

…dann werden beim ersten Aufruf unserer App alle unsere Bücher in IndexedDB gespeichert.

Beim Aktualisieren findet die Bildsynchronisierung statt. Wenn wir also auf einer Seite beginnen, die diese Bilder bereits herunterlädt, sehen wir unseren normalen Service Worker, der sie im Cache speichert (hüstel, vorausgesetzt, wir verzögern den Ajax-Aufruf, um unserem Service Worker eine Chance zu geben, sich zu installieren), was diese Ereignisse in unserem Netzwerk-Tab sind.

Wenn wir dann woanders hin navigieren und aktualisieren, sehen wir keine Netzwerkanfragen für diese Bilder, da unsere Synchronisierungsmethode bereits alles im Cache findet.
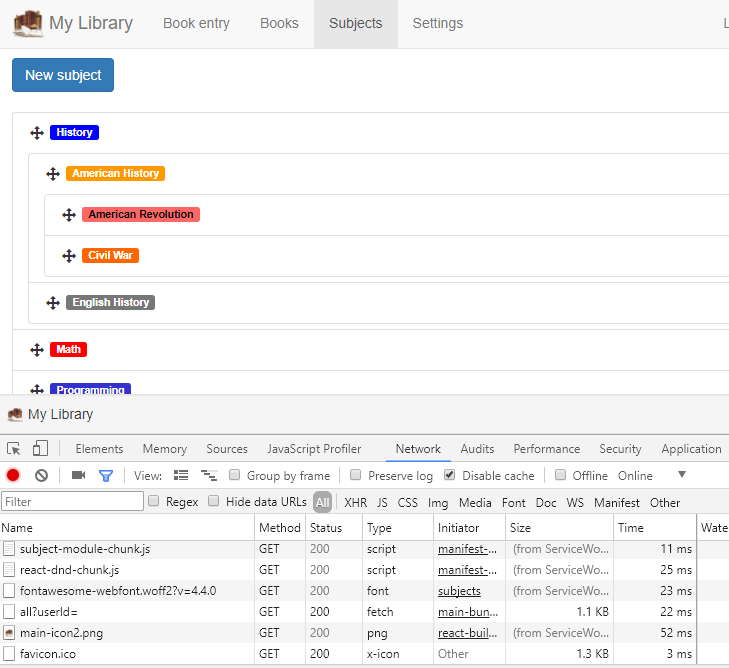
Wenn wir unsere Service Worker erneut löschen und auf derselben Seite beginnen, die diese Bilder **nicht** anderweitig herunterlädt, und dann aktualisieren, sehen wir die Netzwerkanfragen, um diese Bilder herunterzuladen und im Cache zu synchronisieren.

Wenn wir dann zurück zur Seite navigieren, die diese Bilder verwendet, sehen wir keine Aufrufe zum Cachen dieser Bilder, da sie bereits gecacht sind; darüber hinaus sehen wir diese Bilder vom Service Worker aus dem Cache abrufen.

Sowohl unser `runtimeCaching`, bereitgestellt von `sw-toolbox`, als auch unser eigener manueller Code arbeiten zusammen, aus demselben Cache.
Es funktioniert!
Wie versprochen, hier ist die Seite `offline.htm`
<div style="padding: 15px">
<h1>Offline</h1>
<table class="table table-condescend table-striped">
<thead>
<tr>
<th></th>
<th>Title</th>
<th>Author</th>
</tr>
</thead>
<tbody id="booksTarget">
<!--insertion will happen here-->
</tbody>
</table>
</div>let open = indexedDB.open("books");
open.onsuccess = evt => {
let db = open.result;
let transaction = db.transaction("books", "readonly");
let booksStore = transaction.objectStore("books");
var request = booksStore.openCursor();
let rows = ``;
request.onsuccess = function(event) {
var cursor = event.target.result;
if(cursor) {
let book = cursor.value;
rows += `
<tr>
<td><img src="${book.smallImage}" /></td>
<td>${book.title}</td>
<td>${Array.isArray(book.authors) ? book.authors.join("<br/>") : book.authors}</td>
</tr>`;
cursor.continue();
} else {
document.getElementById("booksTarget").innerHTML = rows;
}
};
}Lassen Sie uns Chrome nun sagen, es soll sich als offline ausgeben und es ausprobieren

Cool!
Wohin von hier?
Wir kratzen kaum an der Oberfläche. Ihre Benutzer können diese Daten von mehreren Geräten aus aktualisieren, und jedes davon muss irgendwie synchron bleiben. Sie könnten entweder Ihre IDB-Tabellen periodisch löschen und neu synchronisieren; den Benutzer manuell eine Neusynchronisierung auslösen lassen, wenn er möchte; oder Sie könnten sehr ambitioniert werden und versuchen, all Ihre Mutationen auf Ihrem Server zu protokollieren, und jeden Service Worker auf jedem Gerät alle Änderungen anfordern lassen, die seit seiner letzten Ausführung stattgefunden haben, um sich zu synchronisieren.
Die interessanteste Lösung hier ist PouchDB, das diese Synchronisierung *für Sie* durchführt; der Nachteil ist, dass es für die Arbeit mit CouchDB entwickelt wurde, das Sie vielleicht oder vielleicht auch nicht verwenden.
Synchronisierung lokaler Änderungen
Als letzten Codebetrachtung widmen wir uns einem einfacheren Problem: der Synchronisierung Ihrer IndexedDB mit Änderungen, die gerade jetzt von Ihrem Benutzer, der Ihre Webanwendung verwendet, vorgenommen werden. Wir können Fetch-Anfragen bereits im Service Worker abfangen, daher sollte es einfach sein, auf den richtigen Mutationsendpunkt zu lauschen, ihn auszuführen und dann die Ergebnisse zu prüfen und IndexedDB entsprechend zu aktualisieren. Sehen wir uns das an.
toolbox.router.post(/graphql/, request => {
//just run the request as is
return fetch(request).then(response => {
//clone it by necessity
let respClone = response.clone();
//do this later - get the response back to our user NOW
setTimeout(() => {
respClone.json().then(resp => {
//this graphQL endpoint is for lots of things - inspect the data response to see
//which operation we just ran
if (resp && resp.data && resp.data.updateBook && resp.data.updateBook.Book) {
syncBook(resp.data.updateBook.Book);
}
}, 5);
});
//return the response to our user NOW, before the IDB syncing
return response;
});
});
function syncBook(book) {
let open = indexedDB.open("books", 1);
open.onsuccess = evt => {
let db = open.result;
if (db.objectStoreNames.contains("books")) {
let tran = db.transaction("books", "readwrite");
let booksStore = tran.objectStore("books");
booksStore.get(book._id).onsuccess = ({ target: { result: bookToUpdate } }) => {
//update the book with the new values
["title", "authors", "isbn"].forEach(prop => (bookToUpdate[prop] = book[prop]));
//and save it
booksStore.put(bookToUpdate);
};
}
};
}Dies mag etwas aufwendiger erscheinen, als Sie es sich erhofft hatten. Wir können die Fetch-Antwort nur einmal lesen, und unser Anwendungs-Thread muss sie ebenfalls lesen, daher werden wir zuerst die Antwort klonen. Dann führen wir ein `setTimeout()` aus, damit wir die ursprüngliche Antwort so schnell wie möglich an die Webanwendung/den Benutzer zurückgeben können und danach tun, was wir brauchen. Verlassen Sie sich nicht nur auf das Promise in `respClone.json()`, um dies zu tun, da Promises Microtasks verwenden. Ich werde Jake Archibald erklären lassen, was genau das bedeutet, aber kurz gesagt, sie können die Hauptereignisschleife aushungern. Ich bin nicht schlau genug, um sicher zu sein, ob das hier zutrifft, also habe ich mich einfach für den sicheren Ansatz mit `setTimeout` entschieden.
Da ich GraphQL verwende, sind die Antworten in einem vorhersagbaren Format, und es ist leicht zu erkennen, ob ich gerade die interessierende Operation ausgeführt habe, und wenn ja, kann ich die betroffenen Daten neu synchronisieren.
Weitere Lektüre
Buchstäblich alles hier wird in wunderbarer Tiefe in diesem Buch von Tal Ater erklärt. Wenn Sie mehr erfahren möchten, gibt es keine bessere Lernressource.
Für einige unmittelbarere, schnelle Ressourcen gibt es hier einen MDN-Artikel über IndexedDB und eine Einführung in Service Worker und ein Offline-Kochbuch, beide von Google.
Abschließende Gedanken
Ihren Benutzern nützliche Dinge mit Ihrer Webanwendung tun zu lassen, wenn sie nicht einmal über eine Netzwerkverbindung verfügen, ist eine erstaunliche neue Fähigkeit, die Webentwickler besitzen. Wie Sie gesehen haben, ist es jedoch keine leichte Aufgabe. Hoffentlich hat Ihnen dieser Beitrag eine realistische Vorstellung davon gegeben, was Sie erwartet, und eine gute Einführung in die Dinge, die Sie tun müssen, um dies zu erreichen.
Artikelserie
- Das Setup
- Die Implementierung (hier sind Sie!)
Können Sie das Endergebnis als GitHub-Repo teilen?
Es ist in meinem Booklist-Projekt, auf das in Teil 1 verwiesen wird. Der meiste relevante Service-Worker-Code ist hier zu finden, obwohl
https://github.com/arackaf/booklist/blob/master/react-redux/sw-manual.js
Obwohl vieles davon noch nicht in Gebrauch ist, da ich einige Aktualisierungen an meinem Projekt vornehmen muss, um dies wirklich richtig zu machen – aber es wurde natürlich alles getestet und ausgeführt, als dieser Artikel geschrieben wurde.