GraphQL wird immer beliebter und Entwickler suchen ständig nach Frameworks, die die Einrichtung einer schnellen, sicheren und skalierbaren GraphQL-API erleichtern. In diesem Artikel lernen wir, wie man eine skalierbare und schnelle GraphQL-API mit Authentifizierung und feingranularer Datenzugriffskontrolle (Autorisierung) erstellt. Als Beispiel bauen wir eine API mit Registrierungs- und Anmeldefunktionalität. Die API wird sich mit Benutzern und vertraulichen Dateien befassen, daher werden wir erweiterte Autorisierungsregeln definieren, die festlegen, ob ein angemeldeter Benutzer auf bestimmte Dateien zugreifen kann.
Durch die native GraphQL- und Sicherheitsschicht von FaunaDB erhalten wir alle notwendigen Werkzeuge, um eine solche API in wenigen Minuten einzurichten. FaunaDB hat eine kostenlose Stufe, sodass Sie leicht mitmachen können, indem Sie ein Konto unter https://dashboard.fauna.com/ erstellen. Da FaunaDB automatisch die notwendigen Indizes bereitstellt und jede GraphQL-Abfrage in eine FaunaDB-Abfrage übersetzt, ist Ihre API auch so schnell wie möglich (keine n+1-Probleme!).
Die Einrichtung der API ist einfach: Fügen Sie ein Schema hinzu und wir sind bereit zu beginnen. Fangen wir also an!
Der Anwendungsfall: Benutzer und vertrauliche Dateien
Wir benötigen einen Beispielanwendungsfall, der zeigt, wie Sicherheit und GraphQL-API-Funktionen zusammenarbeiten können. In diesem Beispiel gibt es Benutzer und Dateien. Einige Dateien können von allen Benutzern abgerufen werden, und einige sind nur für Manager bestimmt. Das folgende GraphQL-Schema definiert unser Modell
type User {
username: String! @unique
role: UserRole!
}
enum UserRole {
MANAGER
EMPLOYEE
}
type File {
content: String!
confidential: Boolean!
}
input CreateUserInput {
username: String!
password: String!
role: UserRole!
}
input LoginUserInput {
username: String!
password: String!
}
type Query {
allFiles: [File!]!
}
type Mutation {
createUser(input: CreateUserInput): User! @resolver(name: "create_user")
loginUser(input: LoginUserInput): String! @resolver(name: "login_user")
}Beim Betrachten des Schemas fällt Ihnen vielleicht auf, dass die Mutationsfelder createUser und loginUser mit einer speziellen Direktive namens @resolver annotiert sind. Dies ist eine Direktive, die von der FaunaDB GraphQL-API bereitgestellt wird und es uns ermöglicht, ein benutzerdefiniertes Verhalten für ein gegebenes Query- oder Mutationsfeld zu definieren. Da wir die integrierten Authentifizierungsmechanismen von FaunaDB verwenden werden, müssen wir diese Logik in FaunaDB definieren, nachdem wir das Schema importiert haben.
Importieren des Schemas
Lassen Sie uns zuerst das Beispielschema in eine neue Datenbank importieren. Melden Sie sich mit Ihren Anmeldedaten in der FaunaDB Cloud Console an. Wenn Sie noch kein Konto haben, können Sie sich in wenigen Sekunden kostenlos anmelden.
Sobald Sie angemeldet sind, klicken Sie auf der Startseite auf die Schaltfläche "Neue Datenbank"

Wählen Sie einen Namen für die neue Datenbank und klicken Sie auf die Schaltfläche "Speichern":

Als Nächstes importieren wir das oben aufgeführte GraphQL-Schema in die gerade erstellte Datenbank. Erstellen Sie dazu eine Datei namens schema.gql, die die Schemadefinition enthält. Wählen Sie dann im linken Seitenbereich den Tab GRAPHQL aus, klicken Sie auf die Schaltfläche "Schema importieren" und wählen Sie die neu erstellte Datei aus:

Der Importvorgang erstellt alle notwendigen Datenbankelemente, einschließlich Collections und Indizes, zur Sicherung aller im Schema definierten Typen. Er erstellt automatisch alles, was Ihre GraphQL-API für einen effizienten Betrieb benötigt.
Sie haben jetzt eine voll funktionsfähige GraphQL-API, die Sie im GraphQL-Spielplatz testen können. Aber wir haben noch keine Daten. Genauer gesagt möchten wir einige Benutzer erstellen, um mit dem Testen unserer GraphQL-API zu beginnen. Da Benutzer jedoch Teil unserer Authentifizierung sein werden, sind sie besonders: Sie haben Anmeldedaten und können sich als sie ausgeben. Mal sehen, wie wir Benutzer mit sicheren Anmeldedaten erstellen können!
Benutzerdefinierte Resolver für die Authentifizierung
Erinnern Sie sich an die Mutationsfelder createUser und loginUser, die mit einer speziellen Direktive namens @resolver annotiert sind. createUser ist genau das, was wir brauchen, um mit der Erstellung von Benutzern zu beginnen. Das Schema hat jedoch nicht wirklich definiert, wie ein Benutzer erstellt werden muss; stattdessen wurde es mit einem @resolver-Tag versehen.
Durch das Markieren einer bestimmten Mutation mit einem benutzerdefinierten Resolver wie @resolver(name: "create_user") informieren wir FaunaDB, dass diese Mutation noch nicht implementiert ist, sondern von einer benutzerdefinierten Funktion (UDF) implementiert wird. Da unser GraphQL-Schema dies nicht ausdrücken kann, erstellt der Importvorgang nur eine Funktionsvorlage, die wir noch ausfüllen müssen.
Eine UDF ist eine benutzerdefinierte FaunaDB-Funktion, ähnlich einem gespeicherten Prozedur, die es Benutzern ermöglicht, eine maßgeschneiderte Operation in Fauna's Query Language (FQL) zu definieren. Diese Funktion wird dann als Resolver für das annotierte Feld verwendet.
Wir benötigen einen benutzerdefinierten Resolver, da wir die integrierten Authentifizierungsfunktionen nutzen werden, die sich nicht in Standard-GraphQL ausdrücken lassen. FaunaDB ermöglicht es Ihnen, ein Passwort für jede Datenbankentität festzulegen. Dieses Passwort kann dann verwendet werden, um sich als diese Datenbankentität mit der Funktion Login auszugeben, die einen Token mit bestimmten Berechtigungen zurückgibt. Die Berechtigungen, die dieser Token enthält, hängen von den Zugriffsregeln ab, die wir schreiben werden.
Lassen Sie uns die UDF für den createUser-Feld-Resolver implementieren, damit wir einige Testbenutzer erstellen können. Wählen Sie zuerst den Tab Shell im linken Seitenbereich

Wie bereits erklärt, wurde während des Importvorgangs eine Vorlagen-UDF erstellt. Wenn diese Vorlagen-UDF aufgerufen wird, gibt sie eine Fehlermeldung aus, die besagt, dass sie mit einer ordnungsgemäßen Implementierung aktualisiert werden muss. Um sie mit dem beabsichtigten Verhalten zu aktualisieren, werden wir die Update-Funktion von FQL verwenden.
Kopieren wir also die folgende FQL-Abfrage in die webbasierte Shell und klicken wir auf die Schaltfläche "Abfrage ausführen"
Update(Function("create_user"), {
"body": Query(
Lambda(["input"],
Create(Collection("User"), {
data: {
username: Select("username", Var("input")),
role: Select("role", Var("input")),
},
credentials: {
password: Select("password", Var("input"))
}
})
)
)
});Ihr Bildschirm sollte etwa so aussehen

Die UDF create_user ist für die ordnungsgemäße Erstellung eines Benutzerdokuments zusammen mit einem Passwortwert verantwortlich. Das Passwort wird im Dokument in einem speziellen Objekt namens credentials gespeichert, das verschlüsselt ist und von keiner FQL-Funktion zurückgegeben werden kann. Infolgedessen wird das Passwort sicher in der Datenbank gespeichert, sodass es weder über die FQL- noch über die GraphQL-APIs gelesen werden kann. Das Passwort wird später zur Authentifizierung eines Benutzers über eine spezielle FQL-Funktion namens Login verwendet, wie im Folgenden erläutert.
Fügen wir nun die ordnungsgemäße Implementierung für die UDF hinzu, die den loginUser-Feld-Resolver sichert, indem wir die folgende FQL-Abfrage verwenden
Update(Function("login_user"), {
"body": Query(
Lambda(["input"],
Select(
"secret",
Login(
Match(Index("unique_User_username"), Select("username", Var("input"))),
{ password: Select("password", Var("input")) }
)
)
)
)
});Kopieren Sie die obige Abfrage und fügen Sie sie in das Befehlsfeld der Shell ein und klicken Sie auf die Schaltfläche "Abfrage ausführen"

Die UDF login_user versucht, einen Benutzer mit den angegebenen Benutzernamen- und Passwortanmeldeinformationen zu authentifizieren. Wie bereits erwähnt, geschieht dies über die Funktion Login. Die Funktion Login prüft, ob das eingegebene Passwort mit dem in der Benutzerdokument übereinstimmt, das authentifiziert wird. Beachten Sie, dass das in der Datenbank gespeicherte Passwort während des Anmeldevorgangs zu keinem Zeitpunkt ausgegeben wird. Schließlich gibt die UDF login_user im Falle gültiger Anmeldedaten einen Autorisierungs-Token namens secret zurück, der bei nachfolgenden Anfragen zur Validierung der Benutzeridentität verwendet werden kann.
Nachdem die Resolver vorhanden sind, fahren wir mit der Erstellung einiger Beispieldaten fort. Dies ermöglicht es uns, unseren Anwendungsfall auszuprobieren und besser zu verstehen, wie die Zugriffsregeln später definiert werden.
Erstellung von Beispieldaten
Zuerst erstellen wir einen Manager-Benutzer. Wählen Sie den Tab GraphQL im linken Seitenbereich, kopieren Sie die folgende Mutation in den GraphQL-Spielplatz und klicken Sie auf die Schaltfläche "Play"
mutation CreateManagerUser {
createUser(input: {
username: "bill.lumbergh"
password: "123456"
role: MANAGER
}) {
username
role
}
}Ihr Bildschirm sollte so aussehen

Als Nächstes erstellen wir einen Mitarbeiter-Benutzer, indem wir die folgende Mutation über den GraphQL-Spielplatz-Editor ausführen
mutation CreateEmployeeUser {
createUser(input: {
username: "peter.gibbons"
password: "abcdef"
role: EMPLOYEE
}) {
username
role
}
}Sie sollten die folgende Antwort sehen

Nun erstellen wir eine vertrauliche Datei, indem wir die folgende Mutation ausführen
mutation CreateConfidentialFile {
createFile(data: {
content: "This is a confidential file!"
confidential: true
}) {
content
confidential
}
}Als Antwort sollten Sie Folgendes erhalten

Und schließlich erstellen wir eine öffentliche Datei mit der folgenden Mutation
mutation CreatePublicFile {
createFile(data: {
content: "This is a public file!"
confidential: false
}) {
content
confidential
}
}Wenn erfolgreich, sollte dies folgende Antwort ergeben
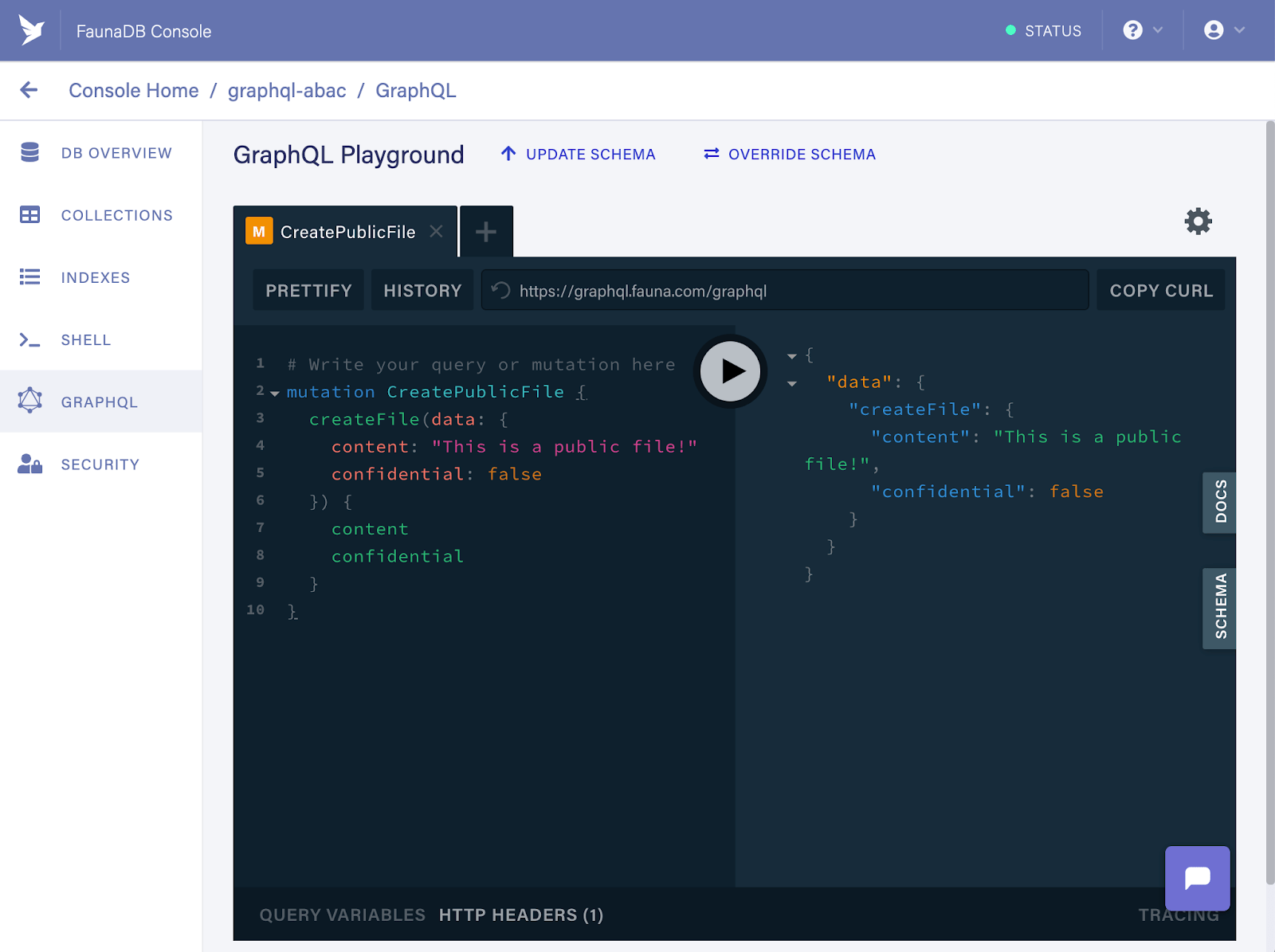
Nachdem nun alle Beispieldaten vorhanden sind, benötigen wir Zugriffsregeln, da sich dieser Artikel mit der Sicherung einer GraphQL-API befasst. Die Zugriffsregeln bestimmen, wie auf die gerade erstellten Beispieldaten zugegriffen werden kann, da ein Benutzer standardmäßig nur auf seine eigene Benutzereinheit zugreifen kann. In diesem Fall werden wir die folgenden Zugriffsregeln implementieren:
- Mitarbeitern erlauben, nur öffentliche Dateien zu lesen.
- Managern erlauben, sowohl öffentliche Dateien als auch nur an Wochentagen vertrauliche Dateien zu lesen.
Wie Sie vielleicht schon bemerkt haben, sind diese Zugriffsregeln sehr spezifisch. Wir werden jedoch sehen, dass das ABAC-System leistungsfähig genug ist, um sehr komplexe Regeln auszudrücken, ohne das Design Ihrer GraphQL-API zu beeinträchtigen.
Solche Zugriffsregeln sind kein Teil der GraphQL-Spezifikation, daher definieren wir die Zugriffsregeln in der Fauna Query Language (FQL) und überprüfen dann, ob sie wie erwartet funktionieren, indem wir einige Abfragen von der GraphQL-API ausführen.
Aber was ist dieses "ABAC"-System, das wir gerade erwähnt haben? Wofür steht es und was kann es tun?
Was ist ABAC?
ABAC steht für Attribute-Based Access Control. Wie der Name schon sagt, ist es ein Autorisierungsmodell, das Zugriffsrichtlinien auf der Grundlage von Attributen festlegt. Einfach ausgedrückt bedeutet dies, dass Sie Sicherheitsregeln schreiben können, die beliebige Attribute Ihrer Daten umfassen. Wenn unsere Daten Benutzer enthalten, könnten wir die Rolle, die Abteilung und die Berechtigungsstufe verwenden, um den Zugriff auf bestimmte Daten zu gewähren oder zu verweigern. Oder wir könnten die aktuelle Uhrzeit, den Wochentag oder den Standort des Benutzers verwenden, um zu entscheiden, ob er auf eine bestimmte Ressource zugreifen kann.
Im Wesentlichen ermöglicht ABAC die Definition von feingranularen Zugriffskontrollrichtlinien, die auf Umwelteigenschaften und Ihren Daten basieren. Jetzt, da wir wissen, was es kann, definieren wir einige Zugriffsregeln, um Ihnen konkrete Beispiele zu geben.
Definieren der Zugriffsregeln
In FaunaDB werden Zugriffsregeln in Form von Rollen definiert. Eine Rolle besteht aus den folgenden Daten
- name — der Name, der die Rolle identifiziert
- privileges — spezifische Aktionen, die auf spezifische Ressourcen ausgeführt werden können
- membership — spezifische Identitäten, die die angegebenen Berechtigungen haben sollten
Rollen werden über die FQL-Funktion CreateRole erstellt, wie im folgenden Beispielausschnitt gezeigt
CreateRole({
name: "role_name",
membership: [ // ... ],
privileges: [ // ... ]
})Man kann zwei wichtige Konzepte in dieser Rolle sehen; Mitgliedschaft und Berechtigungen. Die Mitgliedschaft definiert, wer die Berechtigungen der Rolle erhält, und die Berechtigungen definieren, was diese Berechtigungen sind. Schreiben wir zunächst eine einfache Beispielregel: „Jeder Benutzer kann alle Dateien lesen.“
Da die Regel für alle Benutzer gilt, würden wir die Mitgliedschaft wie folgt definieren:
membership: {
resource: Collection("User")
}Einfach, oder? Dann definieren wir die Berechtigung "Alle Dateien lesen" für alle diese Benutzer.
privileges: [
{
resource: Collection("File"),
actions: { read: true }
}
]Die direkte Auswirkung davon ist, dass jeder Token, den Sie durch die Anmeldung als Benutzer über unsere GraphQL-Mutation loginUser erhalten, nun auf alle Dateien zugreifen kann.
Dies ist die einfachste Regel, die wir schreiben können, aber in unserem Beispiel möchten wir den Zugriff auf einige vertrauliche Dateien beschränken. Um dies zu tun, können wir die Syntax {read: true} durch eine Funktion ersetzen. Da wir definiert haben, dass die Ressource des Privilegs die Sammlung "File" ist, nimmt diese Funktion jede Datei, auf die durch eine Abfrage zugegriffen würde, als ersten Parameter entgegen. Sie können dann Regeln schreiben wie: "Ein Benutzer kann nur auf eine Datei zugreifen, wenn sie nicht vertraulich ist". In FaunaDB's FQL wird eine solche Funktion geschrieben, indem Query(Lambda(‘x’, … <Logik, die Var(‘x’) verwendet>)) verwendet wird.
Unten ist das Privileg, das nur Lesezugriff auf nicht-vertrauliche Dateien gewährt:
privileges: [
{
resource: Collection("File"),
actions: {
// Read and establish rule based on action attribute
read: Query(
// Read and establish rule based on resource attribute
Lambda("fileRef",
Not(Select(["data", "confidential"], Get(Var("fileRef"))))
)
)
}
}
]Dies nutzt direkt Eigenschaften der "File"-Ressource, auf die wir zugreifen wollen. Da es sich nur um eine Funktion handelt, könnten wir auch Umwelteigenschaften wie die aktuelle Uhrzeit berücksichtigen. Schreiben wir zum Beispiel eine Regel, die den Zugriff nur an Wochentagen erlaubt.
privileges: [
{
resource: Collection("File"),
actions: {
read: Query(
Lambda("fileRef",
Let(
{
dayOfWeek: DayOfWeek(Now())
},
And(GTE(Var("dayOfWeek"), 1), LTE(Var("dayOfWeek"), 5))
)
)
)
}
}
]Wie in unseren Regeln erwähnt, sollten vertrauliche Dateien nur für Manager zugänglich sein. Manager sind auch Benutzer, daher benötigen wir eine Regel, die für ein bestimmtes Segment unserer Benutzersammlung gilt. Glücklicherweise können wir auch die Mitgliedschaft als Funktion definieren; zum Beispiel berücksichtigt die folgende Lambda nur Benutzer, die die Rolle MANAGER haben, als Teil der Rollenmitgliedschaft.
membership: {
resource: Collection("User"),
predicate: Query( // Read and establish rule based on user attribute
Lambda("userRef",
Equals(Select(["data", "role"], Get(Var("userRef"))), "MANAGER")
)
)
}Zusammenfassend lässt sich sagen, dass FaunaDB-Rollen sehr flexible Entitäten sind, die es ermöglichen, Zugriffsregeln basierend auf den Attributen aller Systemkomponenten mit unterschiedlichen Granularitätsstufen zu definieren. Der Ort, an dem die Regeln definiert sind — Berechtigungen oder Mitgliedschaft — bestimmt ihre Granularität und die verfügbaren Attribute und variiert je nach individuellem Anwendungsfall.
Nachdem wir nun die Grundlagen der Funktionsweise von Rollen behandelt haben, fahren wir mit der Erstellung der Zugriffsregeln für unseren Beispielanwendungsfall fort!
Um die Dinge ordentlich und übersichtlich zu halten, werden wir zwei Rollen erstellen: eine für jede Zugriffsregel. Dies ermöglicht es uns, die Rollen bei Bedarf mit weiteren Regeln organisiert zu erweitern. Dennoch sei darauf hingewiesen, dass alle Regeln bei Bedarf auch zusammen innerhalb nur einer Rolle definiert werden könnten.
Implementieren wir die erste Regel:
„Mitarbeitern erlauben, nur öffentliche Dateien zu lesen.“
Um eine Rolle zu erstellen, die diese Bedingungen erfüllt, werden wir die folgende Abfrage verwenden
CreateRole({
name: "employee_role",
membership: {
resource: Collection("User"),
predicate: Query(
Lambda("userRef",
// User attribute based rule:
// It grants access only if the User has EMPLOYEE role.
// If so, further rules specified in the privileges
// section are applied next.
Equals(Select(["data", "role"], Get(Var("userRef"))), "EMPLOYEE")
)
)
},
privileges: [
{
// Note: 'allFiles' Index is used to retrieve the
// documents from the File collection. Therefore,
// read access to the Index is required here as well.
resource: Index("allFiles"),
actions: { read: true }
},
{
resource: Collection("File"),
actions: {
// Action attribute based rule:
// It grants read access to the File collection.
read: Query(
Lambda("fileRef",
Let(
{
file: Get(Var("fileRef")),
},
// Resource attribute based rule:
// It grants access to public files only.
Not(Select(["data", "confidential"], Var("file")))
)
)
)
}
}
]
})Wählen Sie den Tab Shell im linken Seitenbereich, kopieren Sie die obige Abfrage in das Befehlsfeld und klicken Sie auf die Schaltfläche "Abfrage ausführen"

Als Nächstes implementieren wir die zweite Zugriffsregel
„Managern erlauben, sowohl öffentliche Dateien als auch nur an Wochentagen vertrauliche Dateien zu lesen.“
In diesem Fall verwenden wir die folgende Abfrage
CreateRole({
name: "manager_role",
membership: {
resource: Collection("User"),
predicate: Query(
Lambda("userRef",
// User attribute based rule:
// It grants access only if the User has MANAGER role.
// If so, further rules specified in the privileges
// section are applied next.
Equals(Select(["data", "role"], Get(Var("userRef"))), "MANAGER")
)
)
},
privileges: [
{
// Note: 'allFiles' Index is used to retrieve
// documents from the File collection. Therefore,
// read access to the Index is required here as well.
resource: Index("allFiles"),
actions: { read: true }
},
{
resource: Collection("File"),
actions: {
// Action attribute based rule:
// It grants read access to the File collection.
read: Query(
Lambda("fileRef",
Let(
{
file: Get(Var("fileRef")),
dayOfWeek: DayOfWeek(Now())
},
Or(
// Resource attribute based rule:
// It grants access to public files.
Not(Select(["data", "confidential"], Var("file"))),
// Resource and environmental attribute based rule:
// It grants access to confidential files only on weekdays.
And(
Select(["data", "confidential"], Var("file")),
And(GTE(Var("dayOfWeek"), 1), LTE(Var("dayOfWeek"), 5))
)
)
)
)
)
}
}
]
})Kopieren Sie die Abfrage in das Befehlsfeld und klicken Sie auf die Schaltfläche "Abfrage ausführen"

An diesem Punkt haben wir alle notwendigen Elemente für die Implementierung und das Ausprobieren unseres Beispielanwendungsfalls erstellt! Fahren wir damit fort, zu überprüfen, ob die von uns erstellten Zugriffsregeln wie erwartet funktionieren…
Alles in Aktion setzen
Beginnen wir mit der Überprüfung der ersten Regel:
„Mitarbeitern erlauben, nur öffentliche Dateien zu lesen.“
Das Erste, was wir tun müssen, ist, uns als Mitarbeiter-Benutzer anzumelden, um zu überprüfen, welche Dateien in seinem Namen gelesen werden können. Führen Sie dazu die folgende Mutation aus der GraphQL-Spielplatz-Konsole aus
mutation LoginEmployeeUser {
loginUser(input: {
username: "peter.gibbons"
password: "abcdef"
})
}Als Antwort sollten Sie einen secret-Zugriffstoken erhalten. Das Secret repräsentiert, dass der Benutzer erfolgreich authentifiziert wurde

An diesem Punkt ist es wichtig zu bedenken, dass die zuvor definierten Zugriffsregeln nicht direkt mit dem Secret verknüpft sind, das als Ergebnis des Anmeldevorgangs generiert wird. Im Gegensatz zu anderen Autorisierungsmodellen enthält der Secret-Token selbst keine Autorisierungsinformationen, sondern ist nur eine Authentifizierungs-Repräsentation eines gegebenen Dokuments.
Wie bereits erläutert, werden Zugriffsregeln in Rollen gespeichert, und Rollen werden über ihre Mitgliedschaftskonfiguration mit Dokumenten verknüpft. Nach der Authentifizierung kann der Secret-Token bei nachfolgenden Anfragen verwendet werden, um die Identität des Aufrufers zu beweisen und zu bestimmen, welche Rollen mit ihm verknüpft sind. Das bedeutet, dass Zugriffsregeln effektiv bei jeder nachfolgenden Anfrage verifiziert werden und nicht nur während der Authentifizierung. Dieses Modell ermöglicht es uns, Zugriffsregeln dynamisch zu ändern, ohne dass sich Benutzer erneut authentifizieren müssen.
Wir verwenden nun das im vorherigen Schritt ausgestellte Secret, um die Identität des Aufrufers in unserer nächsten Abfrage zu validieren. Dazu müssen wir das Secret als Bearer Token als Teil der Anfrage einbeziehen. Um dies zu erreichen, müssen wir den Wert des Authorization-Headers ändern, der vom GraphQL-Spielplatz gesetzt wird. Da wir das Admin-Secret, das als Standard verwendet wird, nicht verpassen möchten, werden wir dies in einem neuen Tab tun.
Klicken Sie auf das Pluszeichen (+), um einen neuen Tab zu erstellen, und wählen Sie dann das Panel HTTP HEADERS unten links im GraphQL-Spielplatz-Editor aus. Ändern Sie dann den Wert des Authorization-Headers, um das zuvor erhaltene Secret wie im folgenden Beispiel gezeigt einzuschließen. Stellen Sie außerdem sicher, dass Sie das Schema von Basic auf Bearer ändern
{
"authorization": "Bearer fnEDdByZ5JACFANyg5uLcAISAtUY6TKlIIb2JnZhkjU-SWEaino"
}Nachdem das Secret korrekt in der Anfrage gesetzt wurde, versuchen wir, alle Dateien im Namen des Mitarbeiter-Benutzers zu lesen. Führen Sie die folgende Abfrage vom GraphQL-Spielplatz aus:
query ReadFiles {
allFiles {
data {
content
confidential
}
}
}In der Antwort sollten Sie nur die öffentliche Datei sehen

Da die für Mitarbeiter definierte Rolle ihnen nicht erlaubt, vertrauliche Dateien zu lesen, wurden diese korrekt aus der Antwort herausgefiltert!
Kommen wir nun zur Überprüfung unserer zweiten Regel
„Managern erlauben, sowohl öffentliche Dateien als auch nur an Wochentagen vertrauliche Dateien zu lesen.“
Diesmal melden wir uns als Mitarbeiter-Benutzer an. Da die Anmeldedaten-Mutation einen Admin-Secret-Token erfordert, müssen wir zuerst zum ursprünglichen Tab mit der Standard-Autorisierungskonfiguration zurückkehren. Dort angekommen, führen Sie die folgende Abfrage aus
mutation LoginManagerUser {
loginUser(input: {
username: "bill.lumbergh"
password: "123456"
})
}Sie sollten als Antwort ein neues Secret erhalten

Kopieren Sie das Secret, erstellen Sie einen neuen Tab und ändern Sie den Authorization-Header so, dass er das Secret wie zuvor als Bearer Token enthält. Führen Sie dann die folgende Abfrage aus, um alle Dateien im Namen des Manager-Benutzers zu lesen
query ReadFiles {
allFiles {
data {
content
confidential
}
}
}Solange Sie diese Abfrage an einem Wochentag ausführen (andernfalls können Sie diese Regel gerne erweitern, um auch Wochenenden einzuschließen), sollten Sie sowohl die öffentliche als auch die vertrauliche Datei in der Antwort erhalten

Und schließlich haben wir überprüft, dass alle Zugriffsregeln erfolgreich von der GraphQL-API aus funktionieren!
Fazit
In diesem Beitrag haben wir gelernt, wie ein umfassendes Autorisierungsmodell über die FaunaDB GraphQL-API unter Verwendung der integrierten ABAC-Funktionen von FaunaDB implementiert werden kann. Wir haben auch die besonderen Fähigkeiten von ABAC überprüft, die es ermöglichen, komplexe Zugriffsregeln basierend auf den Attributen jeder Systemkomponente zu definieren.
Obwohl Zugriffsregeln derzeit nur über die FQL-API definiert werden können, werden sie für jede Anfrage, die gegen die FaunaDB GraphQL-API ausgeführt wird, effektiv überprüft. Die Unterstützung für die Angabe von Zugriffsregeln als Teil der GraphQL-Schema-Definition ist für die Zukunft bereits geplant.
Kurz gesagt, FaunaDB bietet einen leistungsstarken Mechanismus zur Definition komplexer Zugriffsregeln über die GraphQL-API, der die meisten gängigen Anwendungsfälle ohne die Notwendigkeit von Drittanbieterdiensten abdeckt.
Wie würden Sie Passwort-Reset-E-Mails handhaben?
Wenn Sie Reset- oder Bestätigungs-E-Mails benötigen, benötigen Sie dafür eine serverlose Funktion. Es gibt einen Benutzer, der eine Hybridlösung implementiert hat, bei der einige GraphQL-Abfragen von serverlosen Funktionen behandelt und die restlichen an den eigentlichen GraphQL-Endpunkt weitergeleitet werden: https://github.com/ptpaterson/netlify-faunadb-graphql-auth
Wir werden bald selbst etwas schreiben, um das noch klarer zu machen.
Wie würden Sie eine Entität hinzufügen, die ein Benutzer nur als Manager lesen und schreiben kann, aber selektiv die Berechtigung an einen oder mehrere Mitarbeiter erteilen kann?
Auch verschachtelte Daten wären in diesem Beispiel hilfreich.
Teil 2?
Mit ABAC gibt es viele Möglichkeiten, das zu tun. Wir arbeiten an Beispielen, um die Dinge klarer zu machen (hoffentlich können wir diese auch schnell in GraphQL verschieben)
Da man im Wesentlichen zwei Dinge innerhalb jeder ABAC-Berechtigungsfunktion erhält.
- die Entität, auf die Sie zugreifen möchten
- die Identity() der Datenbankentität, die Zugriff möchte.
Ich finde es schwieriger, sich etwas auszudenken, das es nicht kann. Sie könnten zum Beispiel ein Attribut hinzufügen, das beschreibt, welcher Benutzertyp auf eine Entität zugreifen kann (und eine Rolle mit Berechtigungen schreiben, die prüft, ob dieses Attribut vorhanden ist). Manager könnten das natürlich ändern, aber wenn das nicht erwünscht ist, können Sie das auch in diesen Berechtigungen blockieren (prüfen, ob der Schreibvorgang es ändert, bevor Sie einen Schreibvorgang akzeptieren).
Sie könnten neben dem Attribut ein zweites Attribut führen, das die Mitarbeiter auflistet, denen der Manager Zugriff gewährt hat, und auch eine Berechtigungsrolle dafür schreiben.
Ihr Feedback wird sehr geschätzt, wir werden weiter an besseren Beispielen arbeiten, um das, was ich oben geschrieben habe, in Code und Tutorial umzuwandeln :)
Tolles Tutorial – Fauna DB sieht vielversprechend aus, aber ich habe festgestellt, dass Anleitungen/Tutorials schwer zu finden sind, insbesondere in Bezug auf die Authentifizierung, also vielen Dank dafür!
Ich hätte gerne einen Teil 2 im Einklang mit den anderen Fragen
1 – Wie man Dinge wie Passwort-Reset handhabt (oder sich mit Google, Github oder einem alternativen Dienst anmeldet)
2 – Multi-Tenant-Authentifizierung. Grundlegendes Beispiel mit einer To-Do-Listen-App oder einer Notizen-App
Eine Liste kann einen Eigentümer und viele Mitarbeiter haben – alle können lesen/schreiben, aber nur der Eigentümer kann löschen.
Ein Benutzer kann für eine Liste Rolle x, für eine andere Liste aber Rolle y sein (in diesem Fall wäre die Rolle dynamisch).
Nochmals vielen Dank!
Hey, danke für die netten Worte.
Wir sind uns einig, dass wir mehr Authentifizierungs-Tutorials benötigen, einschließlich Auth-Tutorials speziell für GraphQL. Ich arbeite derzeit hart an realen Beispielen, über die wir hoffentlich auf CSS Tricks schreiben werden :)
Bleiben Sie dran!
Vielen Dank, dass Sie eine so detaillierte Anleitung zum Einstieg in FaunaDB geteilt haben. FaunaDB scheint das perfekte Werkzeug für die schnelle Prototypenentwicklung/Erstellung von Endpunkten mit guten ABAC-Funktionen zu sein.
Wie von anderen gefragt, würden wir uns sicherlich über Beispiele/Artikel freuen, die FaunaDB mit Authentifizierungsdiensten wie oAuth, Google usw. abdecken.