Der folgende Beitrag wurde von Catalin Rosu verfasst, der zusammen mit einigen Kollegen eine riesige Menge an Daten über den HTML-Inhalt von Webseiten gesammelt hat. Dies ist die aktuellste Studie dieser Art und die Ergebnisse sind äußerst faszinierend. Besonders spannend finde ich den Vergleich der Top-Ergebnisse mit dem, was ich als Gewinner vermutet hätte.
Wir kennen das alle. Wir versuchen, unseren HTML-Code zu verbessern, ihn sauber, schön und lesbar zu machen. Wir tun dies im Streben nach besserer Semantik und besserer Zugänglichkeit, damit jeder ihn nutzen kann. Das ist unsere oberste Priorität. Und wir haben immer Fragen
- Was ist der beste Weg, das Markup zu strukturieren?
- Wie machen es andere?
Fragen wie diese gingen mir durch den Kopf. Ich fragte mich, wie die Leute heutzutage Markup schreiben, angesichts neuer Webtechnologien. Also tat ich mich mit einigen meiner Kollegen bei AWRCloud zusammen und wir erstellten einen Datensatz von über 8 Millionen Seiten aus den Top-Zwanzig-Ergebnissen von Google.
Die Studien, die dieser vorausgingen
Bereits 2005 führte Ian Hickson, der Herausgeber der HTML5-Spezifikation, eine Analyse von etwas mehr als einer Milliarde Dokumenten durch, um zu sehen, woraus das Web besteht. Eine Milliarde ist eine enorme Zahl, aber für Google ist nichts unmöglich. Mit dieser riesigen Menge an Dokumenten extrahierte er wertvolle Informationen über beliebte Klassennamen, Elemente, Attribute und zugehörige Metadaten. Die herausragenden Ergebnisse wurden später als Web Authoring Statistics veröffentlicht, was bis heute die aussagekräftigste Studie zur Web-Autorenschaft darstellt.
In jüngerer Zeit, im Jahr 2008, analysierte der Crawler der Opera Metadata Analysis and Mining Application, MAMA, etwa 3,5 Millionen URLs. Brian Wilson, der Autor dieser beeindruckenden Arbeit, erweiterte die Studie und veröffentlichte Ergebnisse, die Seitenstrukturen detailliert beschreiben, darunter HTML, CSS und JavaScript.
Eine der Analysen aus den Web Authoring Statistics, die sich später für die Arbeit an der HTML5-Entwicklung als wichtig erwies, war eine Liste der beliebtesten Klassennamen in diesen HTML-Dokumenten. Der Opera MAMA-Crawler suchte auch nach den häufigsten Klassennamen und veröffentlichte zusätzlich zu den Google-Ergebnissen relevante Ergebnisse zu den beliebten Attributwerten für IDs, die Elementen zugewiesen wurden.
Was fügt diese Studie zur Diskussion bei?
Die Daten für diese Studie stammen von 8.021.323 indexierten Seiten, die aus den Top-Zwanzig-Google-Ergebnissen für rund 30 Millionen Keywords, die nach Suchvolumen ausgewählt wurden, gesammelt wurden. Das bedeutet: Wir hatten 30 Millionen Keywords. Wir führten für jedes davon eine Google-Suche durch, nahmen die URLs der Top-20-Ergebnisse und fügten sie der Liste hinzu, wobei Duplikate entfernt wurden.
Wir können nur davon ausgehen, dass die Relevanz dieser Webseiten für die allgemeine Webbevölkerung sehr hoch ist. Dies basiert auf der Wahrscheinlichkeit, dass es sich um beliebte und stark besuchte Websites handelt, die ihren Positionen in den Suchergebnissen entsprechen.
Wie aktuell sind diese Daten?
Der neueste Datensatz stammt vom 20. Mai 2016.
Diese neue Studie wird niemals die frühere Studie von Google aus dem Jahr 2005 übertreffen. Es geht auch nicht darum, die großartige Studie von Opera zu übertreffen. Es geht darum, neue und relevante Einblicke in das tatsächliche Markup zu gewinnen, das von den beliebtesten und erfolgreichsten Webseiten im Internet verwendet wird.
Wie sieht also die durchschnittliche HTML-Seite heute aus? Werfen Sie einen Blick auf die folgenden Screenshots und sehen Sie sich die Studie für die vollständigen Statistiken an.
Die Statistiken
Nach unserer Studie stellen wir fest, dass die durchschnittliche Indexseite einer Website sechsundzwanzig verschiedene Elementtypen verwendet.

Die sechsundzwanzig Elemente, die auf den meisten Seiten verwendet werden, geordnet nach Häufigkeit

<head> und <html> auf allen Websites verwendet. Etwas überraschend ist <body> mit 99% – vielleicht eine sehr große Website mit einem seltsamen Fehler? Die Tabellenelemente am Ende der Liste sind immer noch auf überraschend fast einem Drittel aller Websites zu finden.Unter den Dokumenttypdeklarationen, die die Version von (X)HTML angeben, die eine Seite verwendet, führt der neueste HTML5-Doctype eindeutig das Feld an.

Wenn wir uns alle Elemente ansehen, die speziell dazu dienen, dem Browser oder Suchmaschinen Informationen über die Website und deren Styling zu geben, fanden wir etwa 175 Millionen Elemente, und hier ist ihre Aufschlüsselung:
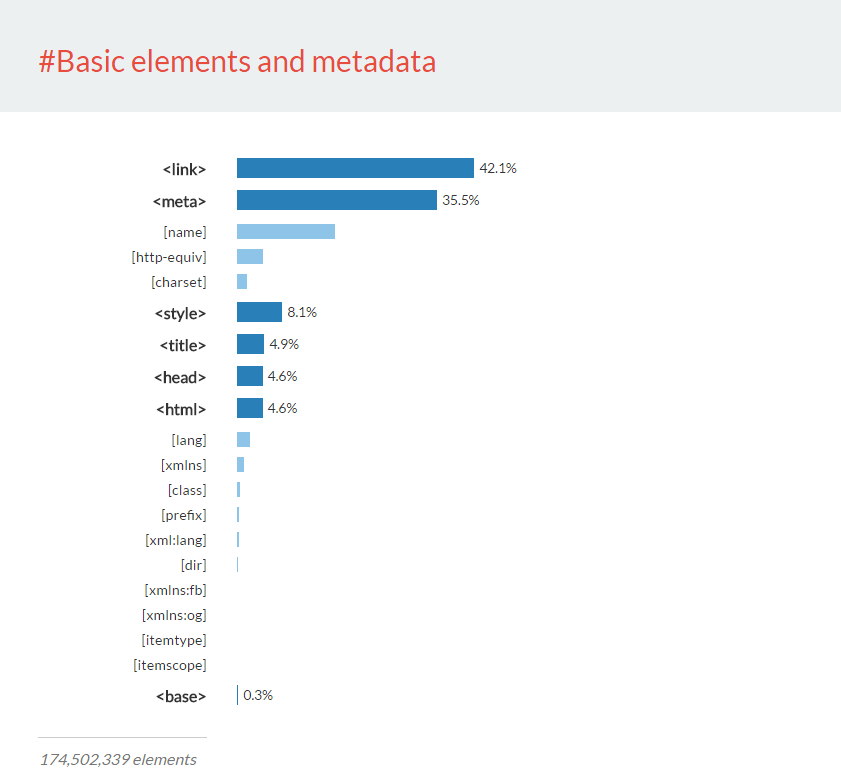
Die Aufschlüsselung der 105 Millionen Elemente für die Inhaltsgliederung sieht wie folgt aus:

<h3>s sind die beliebtesten Überschriftenelemente und das allgemeine Element für die Inhaltsgliederung.Von den einer Milliarde Textelementen

<div> hat eine dominante Führung.Was ist die Zukunft des Webs?
Wir Webentwickler und Web-Content-Ersteller sind neugierig und interessiert an Nutzung, Statistiken und Browserunterstützung. Dies sind die Dinge, die 2005 zu den Erkenntnissen über Klassennamen führten, Namen, die heute als die beliebtesten HTML5-Tags bekannt sind.
Das Web entwickelt sich rasant. Das ist nichts Neues, kann sich aber überwältigend anfühlen. Die Trends ändern sich von Jahr zu Jahr, und als Web-Content-Ersteller erfordert es Motivation und Anstrengung, auf dem Laufenden zu bleiben. Denken Sie darüber nach, wie das Markup und die durchschnittliche Webseite vor zehn Jahren aussahen und wie eine moderne Webseite heute aussieht.
Wir haben die Studie auch genutzt, um aufkommende Technologien wie Web Components zu untersuchen. Während Web Components es Autoren ermöglichen, beliebig benannte Elemente zu erstellen, können wir nach Standardelementen suchen, die bei der Erstellung von Web Components verwendet werden.
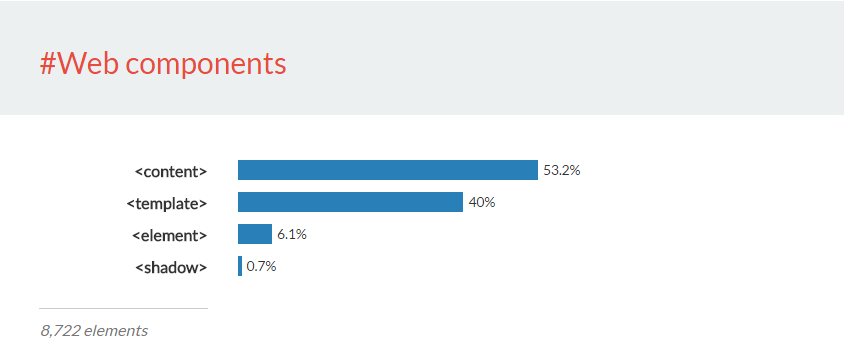
Niemand kann die Zukunft vorhersagen. Wir können nur erraten, wie die durchschnittliche Webseite in zehn Jahren aussehen wird. Werden wir bei der nächsten Durchführung dieser Studie (wir denken über Quartalsberichte nach) sehen, wie Web Components aufsteigen?
Und noch einmal: Der vollständige Datensatz ist hier.
„Die Tabellenelemente am Ende der Liste sind immer noch auf überraschend fast einem Drittel aller Websites zu finden.“ Warum ist das überraschend? Tabellen werden nicht abgeschafft. Sie sind die semantische Art, tabellarische Daten anzuzeigen, wie es sein sollte. Ich bin sicher, viele Websites haben Daten, für die sie Tabellen benötigen.
Obwohl, seien wir ehrlich, viele dieser Tabellen im Internet werden für das Seitenlayout verwendet, aber lassen Sie uns das nicht dem Tabellenelement anlasten.
Ich habe diese Zeile geschrieben – und ja – ich halte es für überraschend, dass ein Drittel aller Webseiten tabellarische Daten enthalten.
Ernsthaft, Chris? Viele Daten lassen sich immer noch einfach und effizient in einer Tabelle darstellen, und Kunden haben immer noch eine verdrehte Liebe zu ihnen, trotz ihrer schrecklichen Reaktionsfähigkeit. Fast jede Website, die ich je erstellt habe, hat mindestens eine Tabelle irgendwo verwendet. Nehmen Sie zum Beispiel E-Commerce-Websites, fast jede davon wird irgendwo eine Tabelle verwenden, sei es für Produktdetails oder Versandinformationen.
Ich denke, das Überraschendste hier ist, dass jemand, der so tief in der Webindustrie verwurzelt ist, die anhaltende Verbreitung von tabellarischen Inhalten auf Websites nicht bemerkt hat.
Ich möchte auch hinzufügen, dass ich überrascht bin, dass ich über etwas nicht überrascht sein darf.
Was es wert ist, ich stimme Chris zu. Ich glaube nicht, dass es da draußen so viele tabellarische Daten gibt. Schauen Sie sich zum Beispiel Yahoo.com an, es gibt viele gemischte Inhalte dort und dennoch verwenden sie
<table role="presentation">zur Behebung eines Stilproblems, nicht für tabellarische Daten.Hey Leute,
Vielleicht ist das Überraschende die Notwendigkeit, tabellarische Daten genau auf den Indexseiten anzuzeigen. Vergessen Sie nicht, dass die obigen Informationen nur für die Indexseiten gelten.
Ich denke hier an die aktuellen Designtrends im Layout und wie sie mit tabellarischen Daten – nicht wirklich – übereinstimmen.
Wird die Verwendung von Divs und Grid-Systemen mehr bevorzugt als eine Tabelle?
Das ist absolut überraschend. Die Tatsache, dass es einen gültigen Anwendungsfall für Tabellen gibt, bedeutet keineswegs, dass ein Drittel aller Websites tabellarische Daten benötigt.
Ich kann kaum Beispiele dafür nennen, was eine durchschnittliche Website in einer Tabelle anzeigen würde.
Was ebenfalls überraschend ist, ist, dass es anscheinend Websites gibt, die
<table>, aber nicht<td>verwenden.Neopets hat möglicherweise die Durchschnittswerte etwas verzerrt. Sie haben seit vielen Jahren kein Redesign mehr durchgeführt, und jede einzelne ihrer Seiten ist mit mehreren verschachtelten Tabellen formatiert. Jede. Einzelne. Seite. Hat. Mehrere. Verschachtelte. Tabellen. Allein der Gedanke daran lässt mich würgen, und dort habe ich als Kind zum ersten Mal gelernt, HTML und CSS zu schreiben. Mein Code ist bis heute so minimalistisch und auf das Wesentliche beschränkt, wie es nur geht, als stille Rebellion dagegen.
Ich denke, die 97% für
<title>sind überraschender, da die Auslassung von Tags für<body>erlaubt ist, aber **nicht** für<title>.Ich nehme an, dass die 99% für Body der Beweis dafür sind, dass die Seiten als Served Documents analysiert wurden und der DOM nach
document.ready(in dem 100% der Seiten einen Body hätten).Ich bin neugierig auf die 10,4 % der Seiten, die keine Anker-Elemente enthalten. Irgendwelche Vorschläge?
vielleicht weil man Aktionen an Mausereignissen anhängen kann, ohne ein Anker-Tag zu benötigen?
Hallo Jonathan,
10,4% der Seiten mit fehlenden Anker-Elementen ist definitiv etwas, das man untersuchen sollte. Ich werde weiter recherchieren und hoffe, mit interessanten Fakten zurückzukommen.
Denken Sie auch daran, dass es einige Websites mit einer Wartungsseite ohne Links gibt.
Für mich ist die überraschendste Erkenntnis in Ihrer Liste der Top 26 Elemente: *strong* ist dabei, aber *b* NICHT! Das zeigt eine Verlagerung der Nutzung hin zu einem semantischeren Ansatz, obwohl es zweifellos auch eine Verlagerung zur Verwendung von CSS zur Änderung von Schriftgewichten widerspiegelt.
Die *table*-Frage ist interessant. Angesichts der Tatsache, dass Ihre Umfrage auf Top-20-Seiten basierte und durch die große Akzeptanz des HTML5-Doctypes verstärkt wurde, scheint Ihre Stichprobe stark auf moderne, aktiv gewartete und aktualisierte Websites ausgerichtet zu sein, deren Umfang sie dazu zwingt, auf neue Entwicklungen und Best Practices zu achten. Wenn das der Fall ist, sollten Sie Ihre Fragestellung zur immer noch erheblichen Nutzung von Tabellen noch einmal überdenken. Haben diese Website-Entwickler vielleicht tatsächlich eine ausgewogene Nutzung von strukturierten Zeilen und Spalten gefunden, wo dies tatsächlich der beste Weg ist, bestimmte Informationen darzustellen? Könnte Ihre zukünftige Umfrage untersuchen, WIE Tabellen verwendet werden – grob gesprochen Seitenstruktur vs. tabellarische Daten?
Schließlich sagen Sie, dass das *h3*-Element die dominierende Überschrift für die Inhaltsgliederung ist. Aber in der Liste der Top 26 Elemente zeigen *h1* und *h2* eine deutlich höhere Nutzung als *h3*. Beziehen sich diese auf unterschiedliche Dinge?
Danke für die Mühe!
Hallo Brue,
Ich stimme zu, dass dieser Teil verwirrend klingen mag, aber lassen Sie mich versuchen, die Dinge etwas klarer zu machen.
Unter den am häufigsten verwendeten 26 HTML-Elementen führen
<h1>und<h2>vor<h3>, weil es um die Häufigkeit geht, nicht um die Gesamtzahl der Vorkommen. Es ist also sehr wahrscheinlich, dass eine Seite einen<h1>oder<h2>enthält, eher als ein<h3>.Auf 8.021.323 Seiten haben wir insgesamt 105.017.877 Elemente zur Inhaltsgliederung gezählt. Hier geht es nur um die Gesamtzahl der Vorkommen und es scheint, dass
<h3>die Nase vorn hat.Ich hoffe, das hilft! :)
Ich bin am meisten betrübt (aber nicht überrascht) zu sehen, dass **Dropdown-Menüs** (bestehend aus mehreren < option >-Elementen) **50%** der Formularelemente ausmachen. Es gibt fast immer eine bessere Option, wie in der wunderbaren Präsentation auf **f-u-c-k-dropdowns.com [ohne die Striche]** angegeben (ich habe keine Zugehörigkeit, ich denke nur, alle Designer sollten sie sich ansehen).
Was für eine lustige Studie. Es scheint, dass es eine weitere Art von einfachen Websites gibt, die nur 9 Arten von HTML-Tags verwenden. Kurz und sauber.
Freut mich, dass Sie das auch bemerkt haben.
Ich habe eine Überprüfung durchgeführt und es gibt 362.769 Websites, die nur 9 verschiedene HTML-Elemente verwenden, im Vergleich zu 473.631 Websites, die 26 Elemente verwenden.
Nur 9 Tag-Typen zu verwenden ist nicht unbedingt „kurz und sauber“ und könnte genauso gut lang und schmutzig sein.
Ich stelle mir zwei wahrscheinliche Fälle für einen merkwürdigen Peak bei genau *N* Tags vor (hier N==9) und bin daran interessiert zu erfahren, ob Catalin bemerkt, ob einer davon zutrifft.
a) Divitis
- Ich sehe viele Seiten mit tiefer Verschachtelung von
<div>s als Wrapper von Wrapper von Wrapper, oft als Teil des Aufbaus einer Website basierend auf einem Framework-System. Man kann oft erkennen, welches Framework es ist, basierend auf den Klassen der Divs.b) Automatisierung
- Wenn ein *E-Z Site Builder v3* Seiten gemäß einer Vorlage erstellt, würden viele ähnliche Seiten und Websites die Daten am *N*-Punkt aufblähen. Da die Automatisierung im Allgemeinen keine Semantik ableiten kann, werden Dinge oft zu generischen Divs.
Stephen,
Das ist sehr interessant.
Im Moment denke ich nur darüber nach, das „Divitis“-Szenario für all die ~300.000 Websites zu untersuchen, die nur diese 9 verschiedenen Elemente verwenden.
Wir haben Abfragen für die ~300.000 Websites durchgeführt, die nur 9 Elemente pro Seite verwenden, und hier sind die Zahlen, die wir für die Top 15 erhalten haben:
meta 2.056.149
script 687.084
link 369.959
div 346.548
head 253.189
html 252.865
title 252.751
body 251.831
p 131.922
h1 116.473
style 112.121
a 72.571
li 53.858
br 15.975
frame 14.414
Die oben genannten sind die Gesamtzahl der HTML-Elemente, die auf ~300.000 Seiten gefunden wurden.
Nicht zwei Drittel, sondern etwa 52,5 %, wenn ich die Daten richtig lese. Von den 8 Mio. Seiten haben nur etwa 6,4 Mio. überhaupt einen Doctyp. Die Daten werden in einer ungewöhnlichen Weise präsentiert, und die relativen Prozentsätze sind nicht sehr nützlich, wenn die Elemente zusammenarbeiten (z.B. area vs map).
Hallo Šime,
Das ist ein guter Punkt, es sind tatsächlich zwei Drittel der Websites, die einen Doctyp angeben.
Auch in Bezug auf die Datenrepräsentation war dies eine der Entscheidungen, die ich zu Beginn dieses Projekts treffen musste. Und bei der Suche nach einer interessanten Möglichkeit, HTML-Elemente nach Funktionalität zu gruppieren, bin ich auf diese beeindruckende MDN-Ressource gestoßen.
Definitiv interessant.
Ich würde vorschlagen, dass die fehlenden 1 % der Body-Elemente auf Frameset-Seiten zurückzuführen sein könnten. Alt und veraltet, aber immer noch in Gebrauch.
Ich bin mehr überrascht über die 11,5 % der skriptlosen Seiten. Vielleicht sind das alles Front-End-Präsentationsseiten?
Die fehlenden 1 % der Body-Elemente sind wieder etwas, das untersucht werden sollte.
Ich vermute, der einzige Weg, dies zu überprüfen, ist, den Parser erneut mit diesen benutzerdefinierten Einstellungen auszuführen und hoffentlich einige interessante Erkenntnisse zu gewinnen.
Großartige Studie! Ich liebe es, solche Aufschlüsselungen zu sehen. Ich bin neugierig, warum
<div>in Text Content und nicht in Content Sectioning enthalten ist. Ältere Seiten (HTML 4.01) würden wahrscheinlich eher<div id="header">anstelle von<header>verwenden, daher bin ich neugierig, wie Sie die Statistiken in die von Ihnen gewählten Kategorien aufgeteilt haben. Ich freue mich auf die nächste Studie, um Trends zu erkennen!Brian, die obigen Kategorien wurden basierend auf der HTML-Elementreferenz von MDN gewählt.
Gibt es eine Chance, dass Sie die Daten Open Source stellen? Ich möchte diese Statistiken etwas genauer untersuchen.
Warum so viele tbody-Elemente? Wird dieser optionale Tag ernsthaft so häufig wie der table-Tag verwendet oder ist es etwas, das der User Agent zum DOM hinzugefügt hat?
Ich habe es mit einer einfachen Tabelle getestet, und Chrome, Safari und Firefox fügen alle automatisch
tbody-Elemente ein.Ich denke, es ist auch erwähnenswert, dass diese Daten sicherlich nur das englischsprachige Web widerspiegeln.
Von den 8.021.323 Seiten, die wir parsen konnten, verwenden 5.368.133 das lang-Attribut im
html-Element. Das sind etwa 70 %!Sehen Sie unten die Aufschlüsselung der
lang-Attributwerte:- **en-US** 2.688.150
- **en** 2.104.991
- **en-gb** 267.844
- **en-GB** 120.406
- **en-us** 54.480
- **de** 40.250
- **fr** 26.156
- **en-AU** 24.133
- **es-ES** 21.561
- **fr-FR** 20.162
Also ja, 99% Englisch.
Viele Frameworks wie fontawesome.io verwenden das
<i>-Tag für Icon-Markup in HTML. Dies könnte erklären, warum<strong>(3,4%) beliebter ist als<b>(2,3%), aber seltsamerweise ist<i>(2,8%) immer noch dominanter als<em>(0,8%). Gedanken?Innerhalb der Gesamtzahl der Inline-Elemente (936.760.353) sind 2,8 % (26.229.289) davon
i-Elemente.Ich habe die
i-Elementstatistiken eingehend untersucht und hier ist die Top 15 für<i class="*"></i>:**fa fa-angle-right** – 696.960
**fa fa-twitter** – 561.335
**fa fa-clock-o** – 543.666
**fa fa-facebook** – 498.275
**fa fa-angle-down** – 455.119
**ddc-icon ddc-icon-chevron-right** – 448.404
**fa fa-user** – 439.849
**fa fa-star** – 409.194
**fa fa-search** – 397.014
**fa fa-google-plus** – 307.473
**fa fa-shopping-cart** – 307.700
**ddc-icon ddc-icon-arrow2-right** – 296.082
**fa fa-bars** – 254.183
**fa fa-heart** – 241.411
**fa fa-envelope** – 244.036
Font Awesome FTW!
Innerhalb der Gesamtzahl der Inline-Elemente (936.760.353) sind 2,8 % (26.229.289) davon
i-Elemente.Also habe ich die
i-Elementstatistiken eingehender untersucht und hier ist die Top 15 für<i class="*"></i>:**fa fa-angle-right** – 696.960
**fa fa-twitter** – 561.335
**fa fa-clock-o** – 543.666
**fa fa-facebook** – 498.275
**fa fa-angle-down** – 455.119
**ddc-icon ddc-icon-chevron-right** – 448.404
**fa fa-user** – 439.849
**fa fa-star** – 409.194
**fa fa-search** – 397.014
**fa fa-google-plus** – 307.473
**fa fa-shopping-cart** – 307.700
**ddc-icon ddc-icon-arrow2-right** – 296.082
**fa fa-bars** – 254.183
**fa fa-heart** – 241.411
**fa fa-envelope** – 244.036
Font Awesome FTW!
Die 15 häufigsten Verwendungen des
<i>-Tags machten etwa 5,5 Millionen von 26,2 Millionen<i>-Tags aus.Wie viele der
<i>-Tags hatten keine Klasse *und* hatten etwas zwischen dem öffnenden und schließenden Tag? Das heißt, wie viele wurden wahrscheinlich für etwas anderes als ein Icon-Font-Element verwendet?Joan, schwer zu sagen, aber nicht unmöglich :)