Ich möchte, dass Sie sich einen Moment Zeit nehmen und an Twitter denken, und zwar im Hinblick auf die Skalierung. Twitter hat 326 Millionen Nutzer. Gemeinsam erstellen wir jede Sekunde ~6.000 Tweets. Jede Minute sind das 360.000 erstellte Tweets. Das summiert sich auf fast 200 Milliarden Tweets pro Jahr. Was wäre, wenn die Entwickler von Twitter durch die Frage, wie sie skalieren sollen, gelähmt gewesen wären und gar nicht erst angefangen hätten?
Das bin ich bei jeder einzelnen Startup-Idee, die ich je hatte, weshalb ich Serverless so liebe: Es kümmert sich um die Skalierungsprobleme und überlässt mir den Aufbau des nächsten Twitters!

Wie Sie oben sehen können, sind wir innerhalb weniger Sekunden von einem auf sieben Server hochskaliert, da mehr Benutzeranfragen eintreffen. Sie können das auch einfach skalieren.
Lassen Sie uns also eine API erstellen, die sofort skaliert, wenn immer mehr Benutzer hinzukommen und unsere Arbeitslast steigt. Wir werden dies tun, indem wir die folgenden Fragen beantworten.
- Wie erstelle ich ein neues Serverless-Projekt?
- Wie führe und debugge ich Code lokal?
- Wie installiere ich Abhängigkeiten?
- Wie verbinde ich mich mit Drittanbieterdiensten?
- Wo kann ich Verbindungszeichenfolgen speichern?
- Wie passe ich den URL-Pfad an?
- Wie kann ich in die Cloud deployen?
Wie erstelle ich ein neues Serverless-Projekt?
Bei jeder neuen Technologie müssen wir herausfinden, welche Tools uns zur Verfügung stehen und wie wir sie in unsere bestehenden Werkzeuge integrieren können. Wenn wir mit Serverless beginnen, haben wir ein paar Optionen zur Auswahl.
Erstens können wir den guten alten Browser verwenden, um Funktionen zu erstellen, zu schreiben und zu testen. Er ist leistungsstark und ermöglicht es uns, überall zu coden; alles, was wir brauchen, ist ein Computer und ein laufender Browser. Der Browser ist ein guter Ausgangspunkt für das Schreiben unserer allerersten Serverless-Funktion.

Wenn Sie sich mit den neuen Konzepten vertrauter machen und produktiver werden, möchten Sie vielleicht Ihre lokale Umgebung nutzen, um Ihre Entwicklung fortzusetzen. Typischerweise benötigen Sie Unterstützung für einige Dinge:
- Code in Ihrem bevorzugten Editor schreiben
- Werkzeuge, die die schwere Arbeit erledigen und den Boilerplate-Code für Sie generieren
- Code lokal ausführen und debuggen
- Unterstützung für schnelles Deployment Ihres Codes
Microsoft ist mein Arbeitgeber und ich habe hauptsächlich Serverless-Anwendungen mit Azure Functions entwickelt. Daher werde ich im Rest dieses Artikels weiterhin diese als Beispiel verwenden. Mit Azure Functions haben Sie Unterstützung für all diese Funktionen, wenn Sie mit den Azure Functions Core Tools arbeiten, die Sie von npm installieren können.
npm install -g azure-functions-core-toolsAls nächstes können wir ein neues Projekt initialisieren und neue Funktionen über die interaktive CLI erstellen.

Wenn Ihr bevorzugter Editor VS Code ist, können Sie ihn auch zum Schreiben von Serverless-Code verwenden. Tatsächlich gibt es dafür eine großartige Erweiterung.
Nach der Installation wird der linken Seitenleiste ein neues Symbol hinzugefügt – hier können wir auf alle unsere Azure-bezogenen Erweiterungen zugreifen! Alle verwandten Funktionen können unter demselben Projekt gruppiert werden (auch bekannt als Funktions-App). Dies ist wie ein Ordner zum Gruppieren von Funktionen, die zusammen skalieren sollen und die wir gleichzeitig verwalten und überwachen möchten. Um ein neues Projekt mit VS Code zu initialisieren, klicken Sie auf das Azure-Symbol und dann auf das **Ordner**-Symbol.

Dadurch werden einige Dateien generiert, die uns bei den globalen Einstellungen helfen. Gehen wir diese nun durch.
host.json
Wir können globale Optionen für alle Funktionen im Projekt direkt in der Datei host.json konfigurieren.
Darin ist unsere Funktions-App so konfiguriert, dass sie die neueste Version der Serverless-Laufzeit (derzeit 2.0) verwendet. Wir konfigurieren auch, dass Funktionen nach zehn Minuten ablaufen, indem wir die Eigenschaft functionTimeout auf 00:10:00 setzen – der Standardwert dafür sind derzeit fünf Minuten (00:05:00).
In einigen Fällen möchten wir möglicherweise das Routenpräfix für unsere URLs steuern oder sogar Einstellungen wie die Anzahl gleichzeitiger Anfragen anpassen. Azure Functions ermöglicht es uns sogar, andere Funktionen wie Protokollierung, healthMonitor und verschiedene Arten von Erweiterungen anzupassen.
Hier ist ein Beispiel, wie ich die Datei konfiguriert habe.
// host.json
{
"version": "2.0",
"functionTimeout": "00:10:00",
"extensions": {
"http": {
"routePrefix": "tacos",
"maxOutstandingRequests": 200,
"maxConcurrentRequests": 100,
"dynamicThrottlesEnabled": true
}
}
}Anwendungseinstellungen
Anwendungseinstellungen sind globale Einstellungen zur Verwaltung von Laufzeit, Sprache und Version, Verbindungszeichenfolgen, Lese-/Schreibzugriff, ZIP-Bereitstellung und vielem mehr. Einige sind für die Plattform erforderliche Einstellungen, wie FUNCTIONS_WORKER_RUNTIME, aber wir können auch benutzerdefinierte Einstellungen definieren, die wir in unserem Anwendungscode verwenden, wie z. B. DB_CONN, mit dem wir eine Datenbankinstanz verbinden können.
Während der lokalen Entwicklung definieren wir diese Einstellungen in einer Datei namens local.settings.json und greifen darauf wie auf jede andere Umgebungsvariable zu.
Auch hier ist ein Beispiel-Snippet, das diese Punkte verbindet.
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "your_key_here",
"FUNCTIONS_WORKER_RUNTIME": "node",
"WEBSITE_NODE_DEFAULT_VERSION": "8.11.1",
"FUNCTIONS_EXTENSION_VERSION": "~2",
"APPINSIGHTS_INSTRUMENTATIONKEY": "your_key_here",
"DB_CONN": "your_key_here",
}
}Azure Functions Proxies
Azure Functions Proxies sind in der Datei proxies.json implementiert und ermöglichen es uns, mehrere Funktions-Apps unter derselben API verfügbar zu machen sowie Anfragen und Antworten zu ändern. Im folgenden Code veröffentlichen wir zwei verschiedene Endpunkte unter derselben URL.
// proxies.json
{
"$schema": "http://json.schemastore.org/proxies",
"proxies": {
"read-recipes": {
"matchCondition": {
"methods": ["POST"],
"route": "/api/recipes"
},
"backendUri": "https://tacofancy.azurewebsites.net/api/recipes"
},
"subscribe": {
"matchCondition": {
"methods": ["POST"],
"route": "/api/subscribe"
},
"backendUri": "https://tacofancy-users.azurewebsites.net/api/subscriptions"
}
}
}Erstellen Sie eine neue Funktion, indem Sie in der Erweiterung auf das **Blitz**-Symbol klicken.
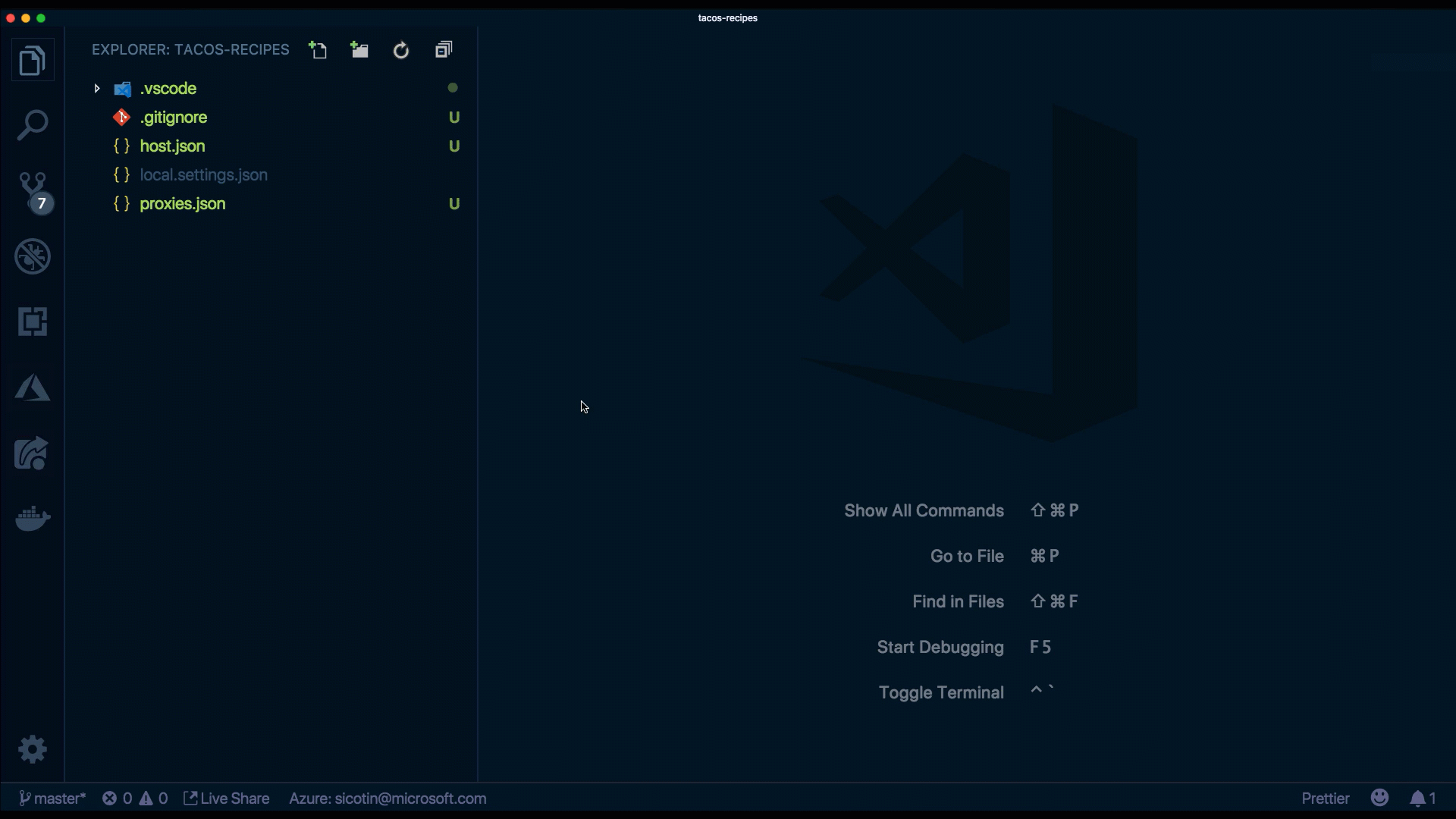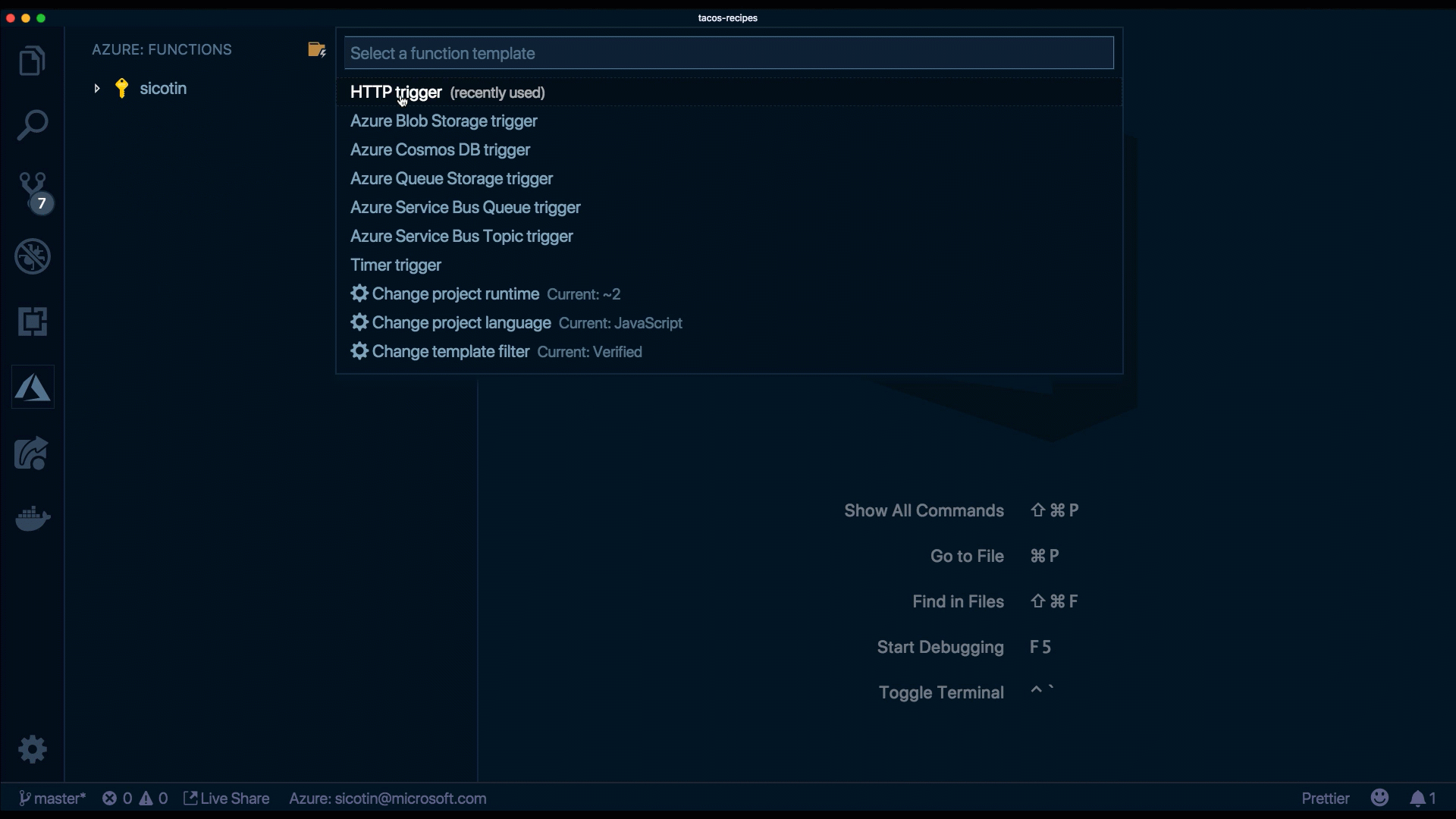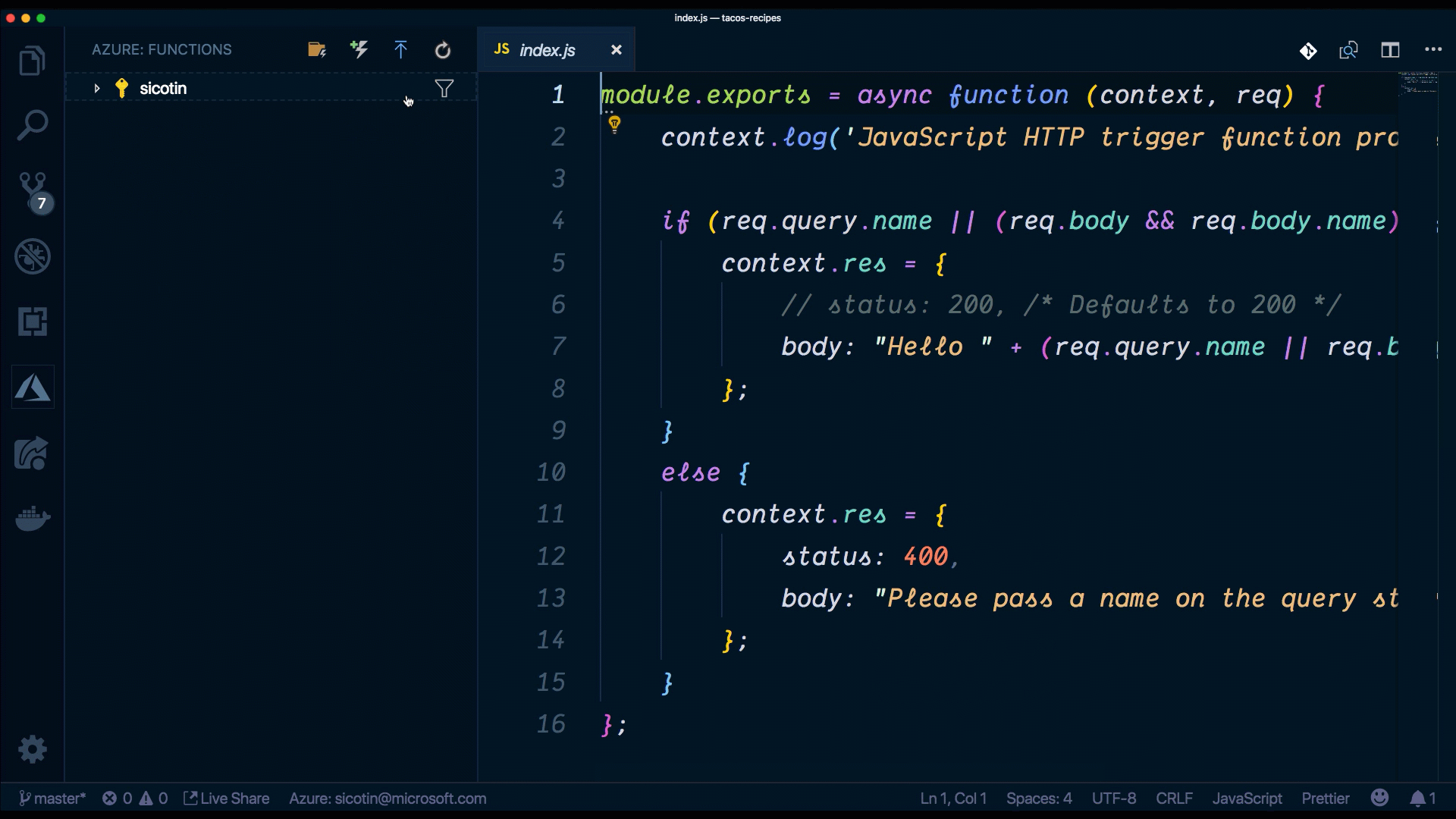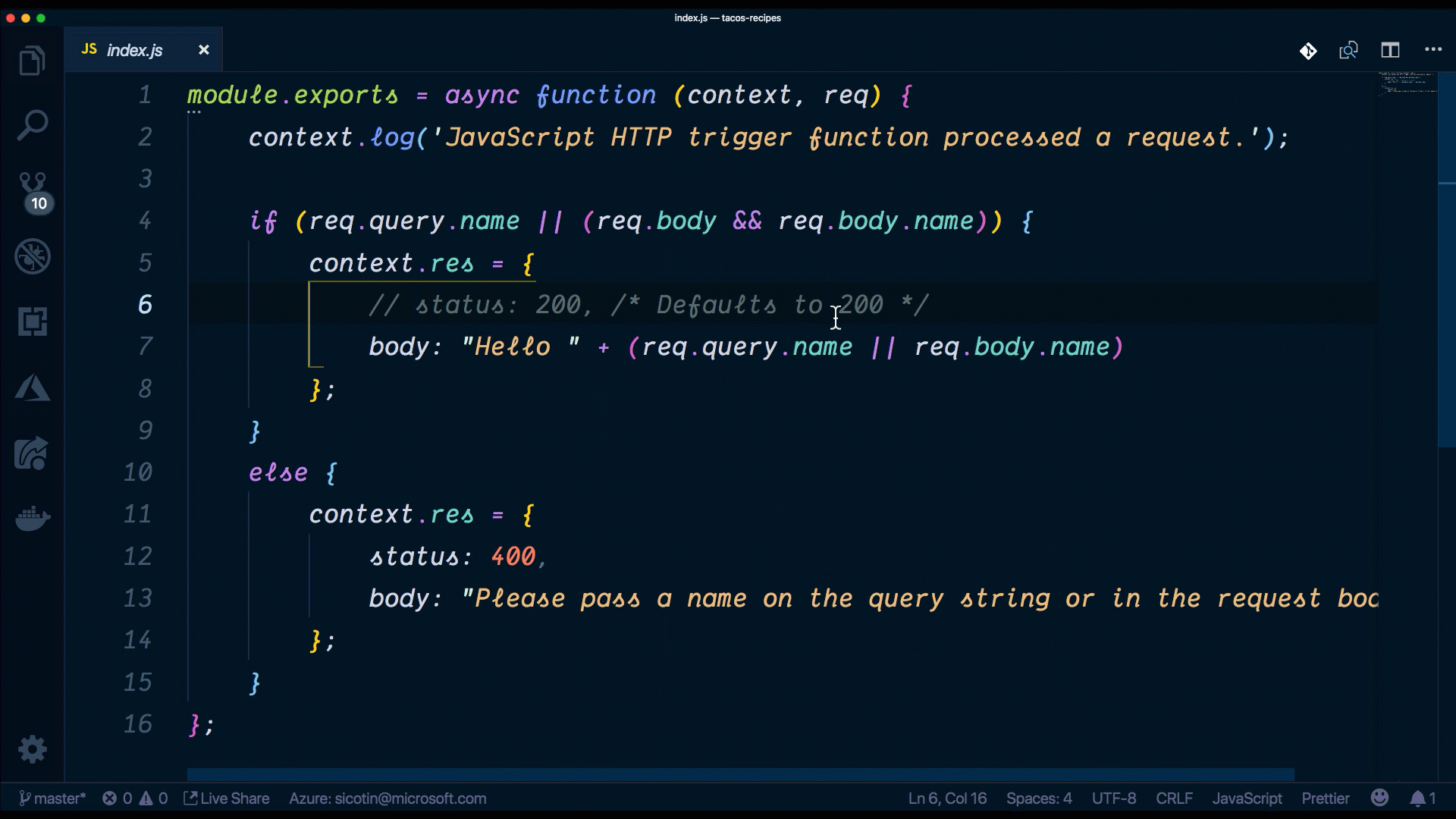
Die Erweiterung verwendet vordefinierte Vorlagen, um Code zu generieren, basierend auf den von uns getroffenen Auswahlen – Sprache, Funktionstyp und Autorisierungsstufe.
Wir verwenden function.json, um zu konfigurieren, auf welche Ereignistypen unsere Funktion hört und optional, um uns an bestimmte Datenquellen zu binden. Unser Code wird als Reaktion auf bestimmte Trigger ausgeführt, die vom **Typ HTTP** sein können, wenn wir auf HTTP-Anfragen reagieren – wenn wir Code als Reaktion auf das Hochladen einer Datei in ein Speicherkonto ausführen. Andere häufig verwendete Trigger können vom **Typ Queue** sein, um eine auf einer Queue hochgeladene Nachricht zu verarbeiten, oder Zeit-Trigger, um Code in bestimmten Zeitintervallen auszuführen. Funktionsbindungen werden verwendet, um Daten aus Datenquellen oder Diensten wie Datenbanken zu lesen und zu schreiben oder E-Mails zu senden.
Hier sehen wir, dass unsere Funktion auf HTTP-Anfragen lauscht und wir über das Objekt req Zugriff auf die eigentliche Anfrage erhalten.
// function.json
{
"disabled": false,
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": ["get"],
"route": "recipes"
},
{
"type": "http",
"direction": "out",
"name": "res"
}
]
}index.js ist der Ort, an dem wir den Code für unsere Funktion implementieren. Wir haben Zugriff auf das Kontextobjekt, das wir verwenden, um mit der Serverless-Laufzeit zu kommunizieren. Wir können Dinge tun wie Informationen protokollieren, die Antwort für unsere Funktion festlegen sowie Daten aus dem bindings-Objekt lesen und schreiben. Manchmal hat unsere Funktions-App mehrere Funktionen, die vom selben Code (z. B. Datenbankverbindungen) abhängen, und es ist eine gute Praxis, diesen Code in eine separate Datei auszulagern, um Code-Duplizierung zu reduzieren.
//Index.js
module.exports = async function (context, req) {
context.log('JavaScript HTTP trigger function processed a request.');
if (req.query.name || (req.body && req.body.name)) {
context.res = {
// status: 200, /* Defaults to 200 */
body: "Hello " + (req.query.name || req.body.name)
};
}
else {
context.res = {
status: 400,
body: "Please pass a name on the query string or in the request body"
};
}
};Wer freut sich darauf, das auszuprobieren?
Wie führe und debugge ich Serverless-Funktionen lokal?
Wenn Sie VS Code verwenden, bietet die Azure Functions-Erweiterung einen Großteil der Einrichtung, die wir zum lokalen Ausführen und Debuggen von Serverless-Funktionen benötigen. Als wir damit ein neues Projekt erstellt haben, wurde automatisch ein Ordner .vscode für uns erstellt, und hier sind alle Debugging-Konfigurationen enthalten. Um unsere neue Funktion zu debuggen, können wir die Befehlspalette (Strg+Umschalt+P) verwenden, indem wir nach Debug: Debugging auswählen und starten filtern oder debug eingeben.

Einer der Gründe, warum dies möglich ist, ist, dass die Azure Functions-Laufzeit Open Source ist und lokal auf unserem Rechner installiert wird, wenn wir das azure-core-tools-Paket installieren.
Wie installiere ich Abhängigkeiten?
Wenn Sie mit Node.js gearbeitet haben, kennen Sie die Antwort auf diese Frage wahrscheinlich schon. Wie in jedem anderen Node.js-Projekt müssen wir zuerst eine package.json-Datei im Stammordner des Projekts erstellen. Das kann durch Ausführen von npm init -y geschehen – das -y initialisiert die Datei mit Standardeinstellungen.
Dann installieren wir Abhängigkeiten mit npm, wie wir es normalerweise in jedem anderen Projekt tun würden. Für dieses Projekt installieren wir nun das MongoDB-Paket von npm, indem wir ausführen:
npm i mongodbDas Paket steht nun zur Verfügung, um in allen Funktionen der Funktions-App importiert zu werden.
Wie verbinde ich mich mit Drittanbieterdiensten?
Serverless-Funktionen sind ziemlich leistungsfähig und ermöglichen es uns, benutzerdefinierten Code zu schreiben, der auf Ereignisse reagiert. Aber Code allein hilft nicht viel beim Erstellen komplexer Anwendungen. Die wahre Leistung liegt in der einfachen Integration mit Drittanbieterdiensten und -werkzeugen.
Wie verbinden wir uns also mit einer Datenbank und lesen Daten daraus? Mit dem MongoDB-Client lesen wir Daten aus einer Azure Cosmos DB-Instanz, die ich in Azure erstellt habe, aber Sie können dies mit jeder anderen MongoDB-Datenbank tun.
//Index.js
const MongoClient = require('mongodb').MongoClient;
// Initialize authentication details required for database connection
const auth = {
user: process.env.user,
password: process.env.password
};
// Initialize global variable to store database connection for reuse in future calls
let db = null;
const loadDB = async () => {
// If database client exists, reuse it
if (db) {
return db;
}
// Otherwise, create new connection
const client = await MongoClient.connect(
process.env.url,
{
auth: auth
}
);
// Select tacos database
db = client.db('tacos');
return db;
};
module.exports = async function(context, req) {
try {
// Get database connection
const database = await loadDB();
// Retrieve all items in the Recipes collection
let recipes = await database
.collection('Recipes')
.find()
.toArray();
// Return a JSON object with the array of recipes
context.res = {
body: { items: recipes }
};
} catch (error) {
context.log(`Error code: ${error.code} message: ${error.message}`);
// Return an error message and Internal Server Error status code
context.res = {
status: 500,
body: { message: 'An error has occurred, please try again later.' }
};
}
};Eine Sache, die hier zu beachten ist, ist, dass wir unsere Datenbankverbindung wiederverwenden, anstatt für jeden nachfolgenden Aufruf unserer Funktion eine neue zu erstellen. Das spart ~300 ms bei jedem nachfolgenden Funktionsaufruf. Ich nenne das einen Gewinn!
Wo kann ich Verbindungszeichenfolgen speichern?
Beim lokalen Entwickeln können wir unsere Umgebungsvariablen, Verbindungszeichenfolgen und alles andere Geheime in der Datei local.settings.json speichern und dann wie gewohnt über process.env.yourVariableName darauf zugreifen.
local.settings.json
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "",
"FUNCTIONS_WORKER_RUNTIME": "node",
"user": "your-db-user",
"password": "your-db-password",
"url": "mongodb://your-db-user.documents.azure.com:10255/?ssl=true"
}
}In der Produktion können wir die Anwendungseinstellungen auf der Seite der Funktion im Azure-Portal konfigurieren.

Eine weitere nette Möglichkeit, dies zu tun, ist jedoch über die VS Code-Erweiterung. Ohne Ihre IDE zu verlassen, können wir neue Einstellungen hinzufügen, vorhandene löschen oder sie in die Cloud hoch- und herunterladen.
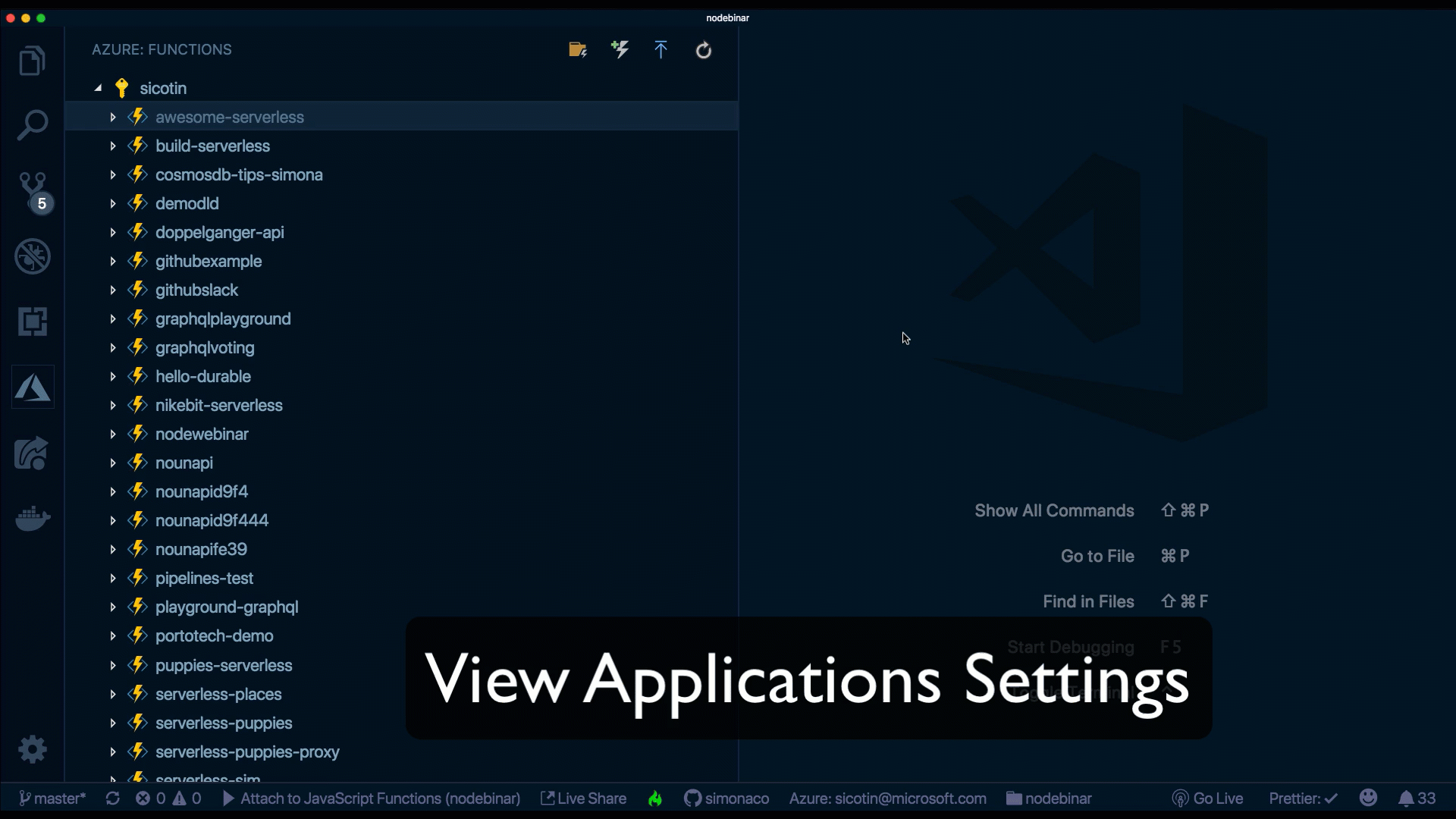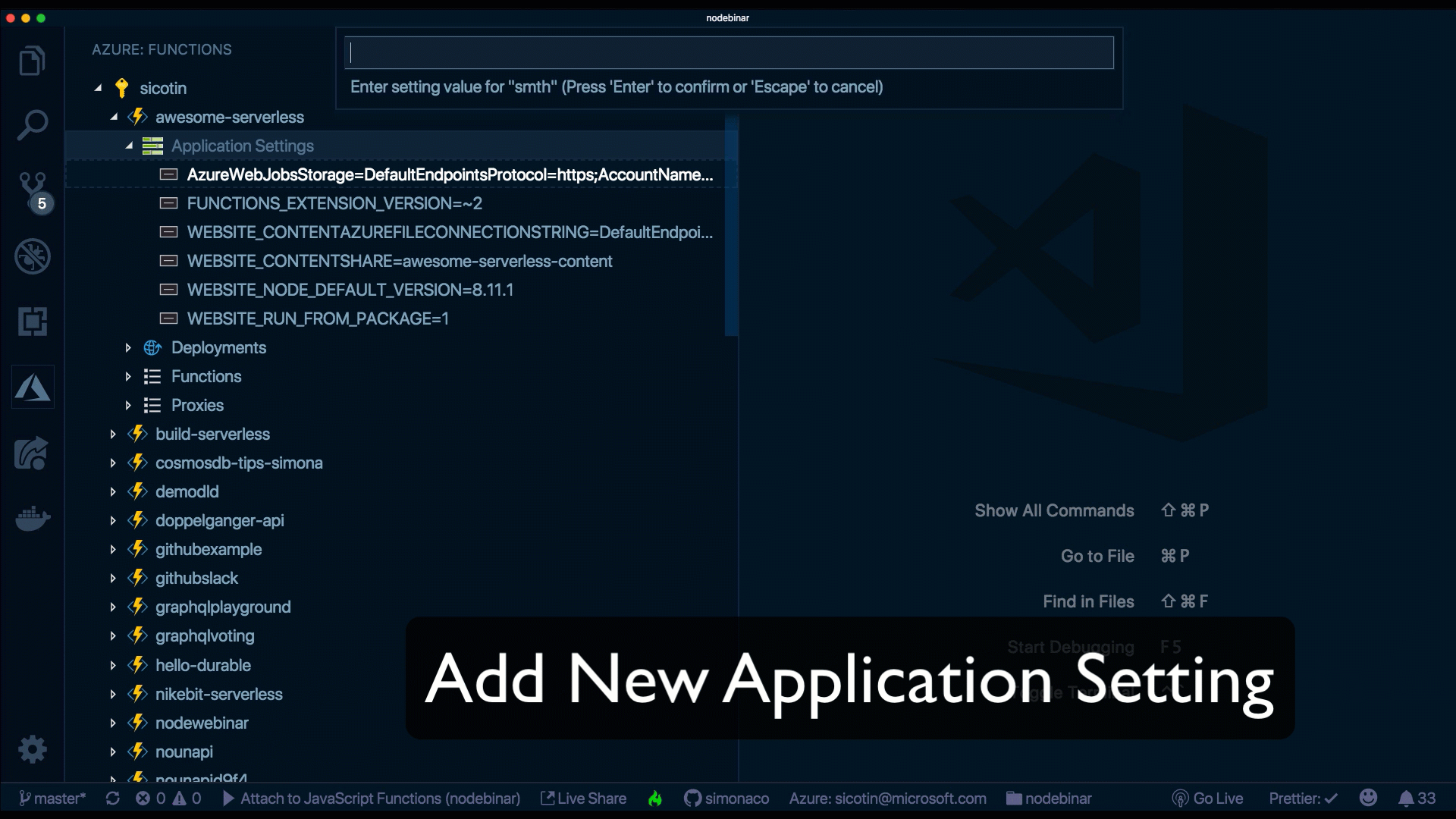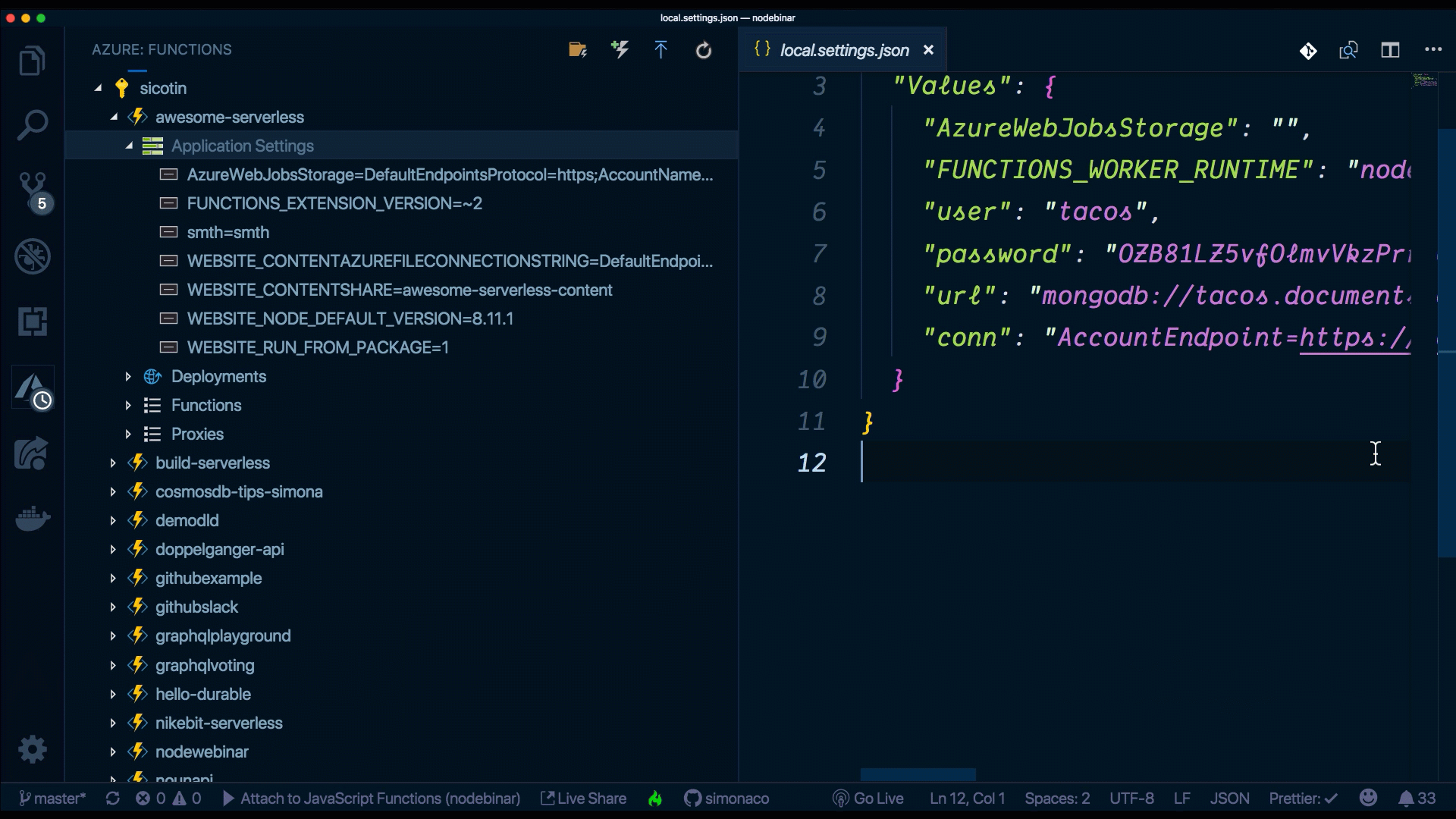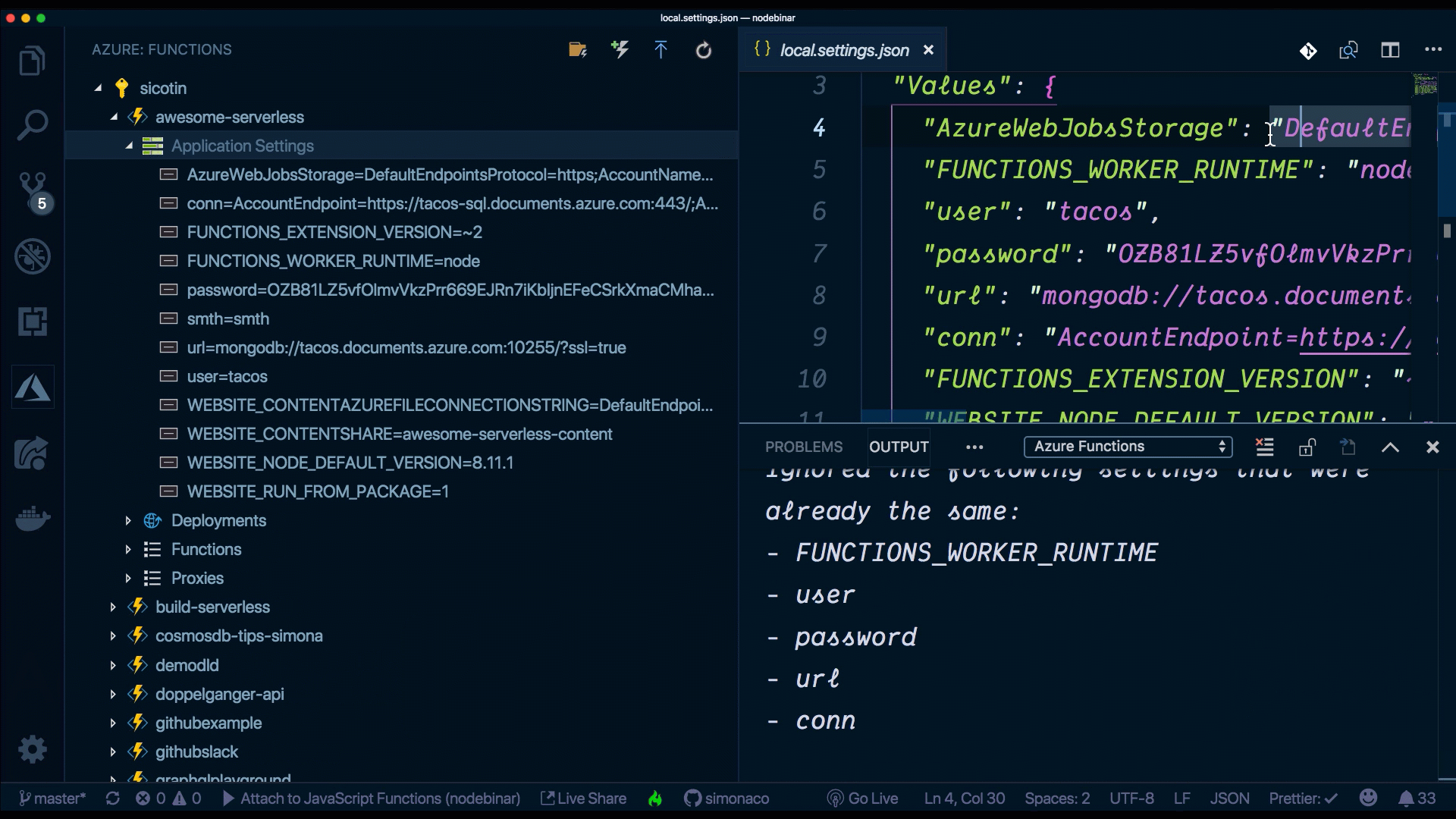
Wie passe ich den URL-Pfad an?
Bei der REST-API gibt es einige Best Practices für das Format der URL selbst. Die, die ich für unsere Recipes API gewählt habe, ist:
GET /recipes: Ruft eine Liste von Rezepten abGET /recipes/1: Ruft ein bestimmtes Rezept abPOST /recipes: Erstellt ein neues RezeptPUT /recipes/1: Aktualisiert das Rezept mit ID 1DELETE /recipes/1: Löscht das Rezept mit ID 1
Die URL, die standardmäßig bei der Erstellung einer neuen Funktion verfügbar ist, hat das Format http://host:port/api/function-name. Um den URL-Pfad und die Methode, auf die wir lauschen, anzupassen, müssen wir sie in unserer function.json-Datei konfigurieren.
// function.json
{
"disabled": false,
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": ["get"],
"route": "recipes"
},
{
"type": "http",
"direction": "out",
"name": "res"
}
]
}Darüber hinaus können wir Parameter zum Routen unserer Funktion hinzufügen, indem wir geschweifte Klammern verwenden: route: recipes/{id}. Wir können den ID-Parameter dann in unserem Code aus dem req-Objekt lesen.
const recipeId = req.params.id;Wie kann ich in die Cloud deployen?
Herzlichen Glückwunsch, Sie haben es bis zum letzten Schritt geschafft! 🎉 Zeit, diese Köstlichkeiten in die Cloud zu pushen. Wie immer hat die VS Code-Erweiterung alles im Griff. Mit einem einzigen Rechtsklick sind wir so gut wie fertig.

Die Erweiterung packt den Code mit den Node-Modulen in ein ZIP und schickt alles in die Cloud.
Während diese Option großartig ist, wenn wir unseren eigenen Code testen oder vielleicht an einem kleinen Projekt arbeiten, ist es leicht, versehentlich die Änderungen anderer zu überschreiben – oder schlimmer noch, die eigenen.
Lassen Sie nicht zu, dass Freunde per Rechtsklick deployen!
- Jeder DevOps-Ingenieur da draußen
Eine gesündere Option ist die Einrichtung von GitHub-Deployment, was in ein paar Schritten im Azure-Portal über die Registerkarte **Deployment Center** erfolgen kann.

Sind Sie bereit, Serverless-APIs zu erstellen?
Dies war eine gründliche Einführung in die Welt der Serverless-APIs. Es gibt jedoch noch viel mehr, als wir hier behandelt haben. Serverless ermöglicht es uns, Probleme kreativ und zu einem Bruchteil der Kosten zu lösen, die wir normalerweise für traditionelle Plattformen bezahlen.
Chris hat es in anderen Beiträgen hier auf CSS-Tricks erwähnt, aber er hat diese hervorragende Website erstellt, auf der Sie mehr über Serverless erfahren und sowohl Ideen als auch Ressourcen für Dinge finden können, die Sie damit bauen können. Schauen Sie sich das unbedingt an und lassen Sie mich wissen, ob Sie weitere Tipps oder Ratschläge zum Skalieren mit Serverless haben.
RE: „Wir können den guten alten Browser verwenden, um Funktionen zu erstellen, zu schreiben und zu testen.“ – Was ist das für ein Screenshot? Wie genau könnten wir das tun?
Hallo Derek! Danke fürs Lesen. Ich habe ein Video mit den Schritten zur Erstellung einer neuen Funktion über das Azure-Portal aufgezeichnet, das Sie hier ansehen können: https://youtu.be/6WMIGlxcL7I. Es gibt auch detaillierte Schritte auf der Dokumentationsseite: https://docs.microsoft.com/en-us/azure/azure-functions/functions-create-first-azure-function. Ich hoffe, das hilft.
Hallo Simona,
Das ist sehr hilfreich. Danke :)
Ich lerne gerade Azure Functions und Cosmo DB (bin ein absoluter Anfänger) und sehe, dass man Cosmo DB-Bindungen für „in“ (was die Ergebnisse einer Abfrage liefert) oder „out“ (was in Cosmo DB schreibt) einrichten kann. Haben Sie eine Idee, wie sich die Verwendung dieser Bindungen mit einer direkten Verbindung im Body der Azure-Funktion vergleichen lässt?